1 当前集群面临的主要问题
1.1 机房空间的限制
随着公司线上化业务的高速进展,Hadoop集群面临了大量的数据接入压力。然而当前大数据集群所在的亦庄机房已经无法承载过多的机器,因此有必要进行一次数据搬迁。
1.2 集群的规范
Hadoop集群已经从XX年的XX台机器增长到如今近XX台机器的规模。原来集群的规范和使用,已经无法满足大规模集群的要求。旧集群现在诸多问题(此处涉密省略),在加上旧机房空间不足,因此有必要进行一次数据搬迁和集群升级和集群规范体系的重构。因此我们于2020年启动了Hadoop集群数据搬迁与升级项目。
2 Hadoop集群数据搬迁与升级项目架构
对Hadoop集群数据搬迁和升级项目有如下目标,我们需要保证如下两个目标的前提下设计项目架构。
尽可能降低在项目实施过程中用户的接入成本。
计算任务运行速度不因数据搬迁和集群版本升级而下降。
考虑到数据搬迁的过程不可能一次将旧机房的全部机器迁移到新机房中,因此会面临着多集群的管理的过程。传统多机房的架构,会在不同的机房独立建立不同的集群,不同集群之间数据是完全隔离开的。如果想将集群DC1的数据迁移到集群DC2上,需要配置一组distcp任务进行数据迁移。如果DC2集群的任务对DC1集群的数据有数据依赖,必须人为地配置一组专门进行数据同步的任务,将数据拷贝到DC2集群。
关于Hadoop集群版本的升级,主要有两种传统的技术方案。第一种方案是原地进行升级。第二种方案是搭建新版本集群,将旧版本集群不断地迁移到新集群上。正如前面描述旧集群存在诸多问题,我们决定将旧版集群的数据一点点迁移到新版集群,在这个过程中实现集群版本升级。同时,针对这种增量搬迁和升级方法,也降低了集群升级带来的风险。因此我们选择方案二。
2.1 传统的数据搬迁方案
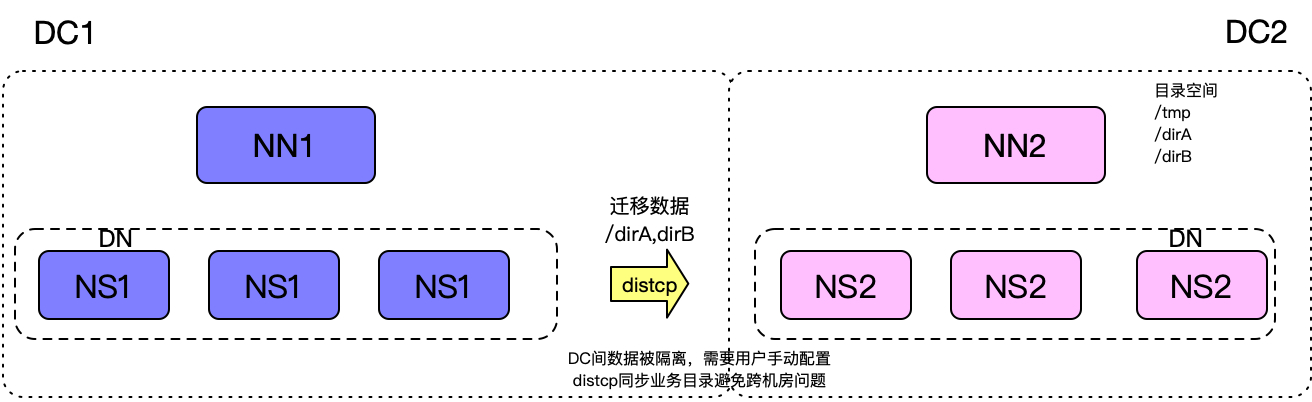
传统的技术方案有这这样的问题:
集群间数据隔离,无法有效共享。
如果DC2集群有任务依赖于DC1机房的数据,必须增加一组前置的distcp任务。这对集群上数以十万计算的存量任务来说,增加前置任务对用户来说就是灾难。
数据搬迁过程中,对于大量的存量数据,需要人为地梳理业务路径,配置大量的distcp同步任务拷贝数据,浪费大量的人力资源,甚至可能要花费一个团队的资源去做人工干预。
2.2 我们的数据搬迁方案
为了实现第一个目标,我们使用RBF,通过切换Mountable实现数据迁移。为了实现第二个目标,我们通过跨机房缓存策略尽可能避免跨机房的数据访问。
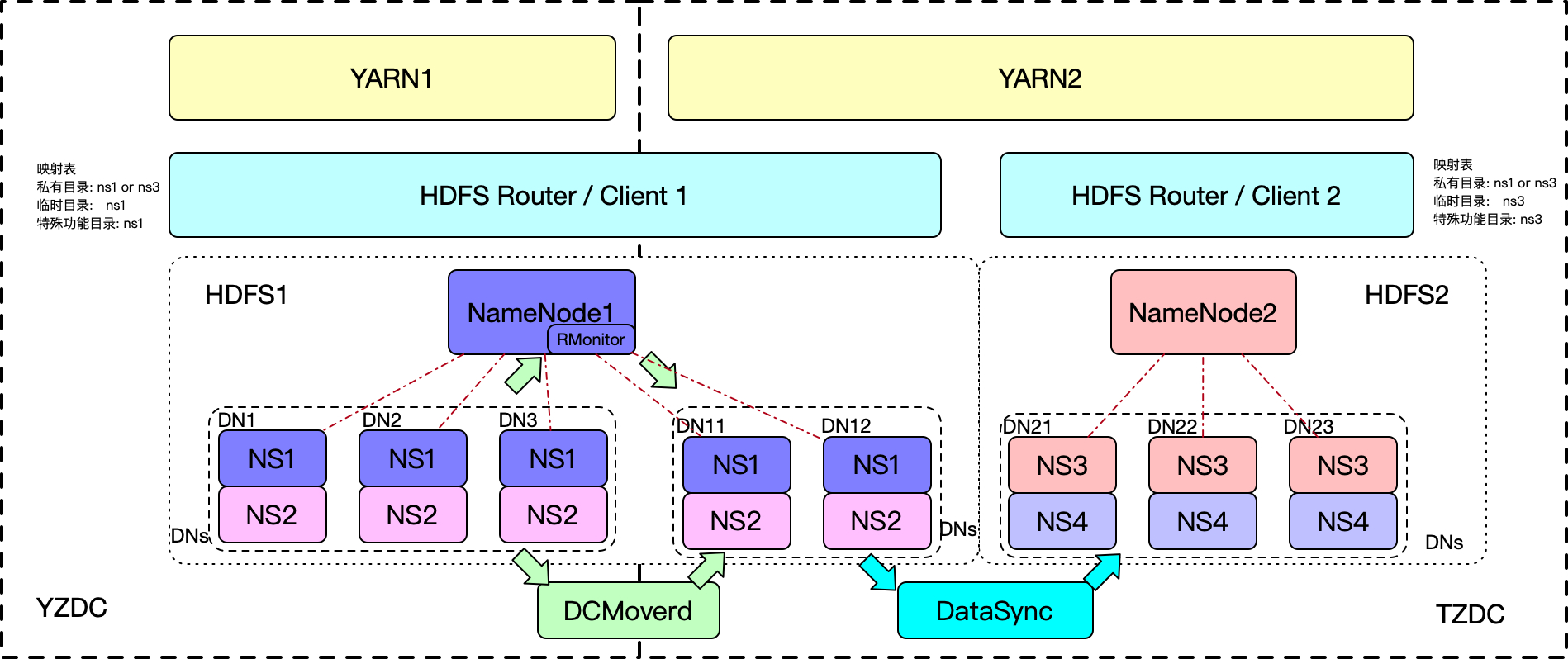
初始条件下在DC1有原始的集群HDFS1,然后通过跨机房技术在DC2启动该HDFS1集群对应的数据节点。同时在DC2机房启动最新版本Hadoop-3.2.1搭建的新集群HDFS2。再两个HDFS集群分别启动两组DFSRouter实现RBF功能,实现完整统一的数据视图。对于Yarn,由于计算层面上的Shuffle过程是数据量极大且难以有效缓存控制,同时在计算层面上也没有跨机房的需求,因此计算层面上没有跨机房,因此每个机房单独启动一个Yarn集群。
这里涉及的特殊组件的描述如下:
ReplicationMonitor为NameNode的后台线程,会不断复制或删除不满足副本要求的副本。这里对其进行改进,支持多机房维度的改造,会处理复制和删除不满足机房维度副本要求的的副本。
DataSync为一个同步组件,会自动生成Distcp同步任务,将数据不断地同步到新机房。
DCMoverd为一个辅助机房副本放置组件,会不断地抓取源nameservice的editlog,并检查是否满足副本要求,从而拷贝副本。为了让下游业务尽可能读取同机房副本,我们需要尽快将副本同步到指定机房。事实上ReplicationMonitor已经根据策略调整机房维度的副本了,但是考虑到下线等操作会降低ReplicationMonitor调度其他副本速度。因此,开发该辅助组件。
具体的迁移流程大致如下:
首先我们通过自动化组件DataSync设置要迁移的数据目录,D自动地生成Distcp拷贝任务。DataSync以后台任务的形式不断地启动同步任务。
将该业务目录的Mountable执行新集群的HDFS,客户端切换指向新集群对应的客户端,即完成了业务的迁移。
在进行数据同步的时候,需要对要缓存的数据目录设置跨机房策略。我们会根据任务依赖关系查找出已经迁移到新机房的任务对那些数据有依赖关系,对这些数据我们会配置上多机房副本放置策略,保证任务尽可能读到在同机房缓存的数据。同时启动DCMoverd进行辅助同步。不过实际实施的时候我们使用后面提到的hook机制来动态设置跨机房策略,并没有使用DCMoverd。
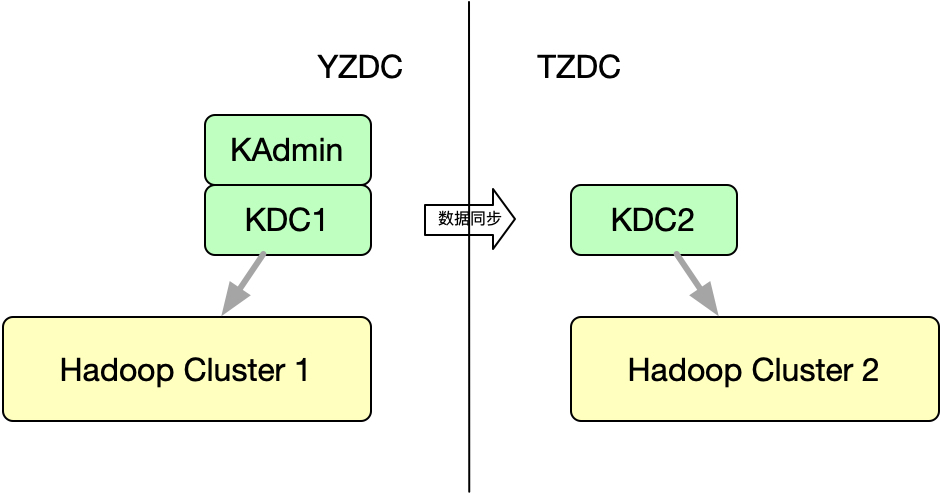
2.3 跨集群认证问题
对于大数据集群的主要组件的迁移,基本上采取搭建影子环境的方式逐步迁移。但是对于KDC,为了达到用户无感知的要求,多集群必须使用的KDC必须同域。为了避免跨机房认证,同时尽可能避免跨机房带宽可能带来的不稳定因素。我们在目标机房也启动一组KDC任务,会通过kprop不断地将KDC1中的数据库不断地同步到KDC2中,即实现了跨机房场景下的Kerberos认证。当所有数据均迁移到目标机房后,会关闭KDC1和KAdmin,并在目标机房上启动KAdmin,即实现Kerberos服务的迁移。
2.4 兼容性问题
由于集群从Hadoop-2.7.3升级到Hadoop-3.2.1,这个过程中发生了大量的API库修改的问题以及依赖库版本变化的问题。我们对诸如Hive,Tez,Spark等框架相关版本做关于相应的兼容性改造。另外,集群也存在大量的UDF的依赖库与新集群版本不兼容(譬如guava等),这个是需要业务方进行相关的版本升级或者使用maven-shade-plugin隔离版本。
2.5 总结
虽然我项目的目标是以数据搬迁为主。事实上过程中,该方案已经是一套完整的多机房集群建设方案。
本节内容主要介绍了整体的方案,第三、四小节将重点介绍下该方案是如何实现前面介绍的两个目标的。其中第三小节将解释通过什么样的方案实现”计算任务运行速度不因数据搬迁和集群版本升级而下降”,第四小节将解释如何尽可能降低在项目实施过程中用户的接入成本。
3 跨机房HDFS集群
本小节介绍多机房HDFS技术的原理,即主要介绍在单个HDFS集群在多机房部署场景下应用。该部分内容主要用于解决前文提出的“计算任务运行速度不因数据搬迁和集群版本升级而下降”的问题。
3.1 问题分析
数据中心机房带宽往往属于稀缺资源,我们只有800G的非独享带宽。高负载的网络带宽不仅仅会限制设备间的数据传输,而且还可能影响部分服务的网络延时。大数据集群有着数据交换量大的特点,因此必然会占用大量的网络带宽。那么如何降低Hadoop集群机房间的网络流量就是跨机房Hadoop集群主要问题。
那么如何尽可能降低跨机房带宽呢?主要有如下两个关键点:
写数据一定写到本机房。
读数据优先读本机房的策略。
用下面的一个例子分析:
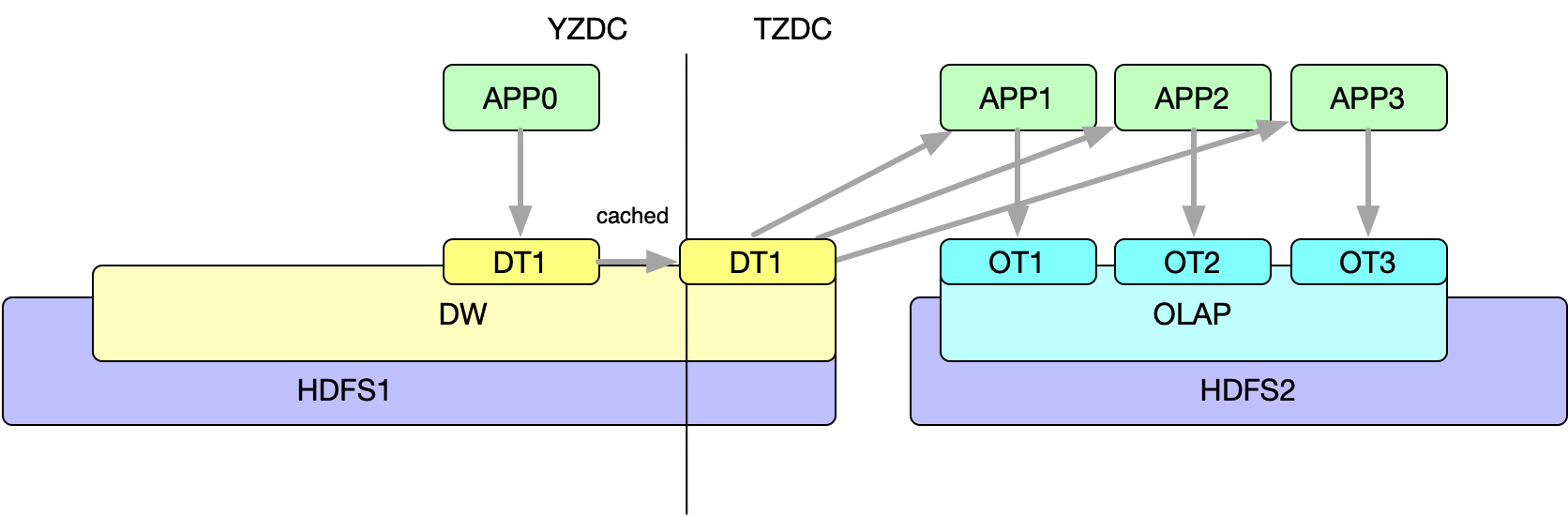
图中,YZDC表示源机房,TZDC表示目的机房。图中的分割线表示机房的界限。其中HDFS1的数据节点是即部署在源机房,也部署在目的机房。
假设OLAP层的数据已经迁移到TZDC的HDFS2上,同时产生OLAP表的任务也会迁移到TZDC,而DW层的任务仍然在YZDC。在YZDC运行的APP0会产生表DT1,在TZDC运行的APP1-3会产生OT1-3三个表。由于存在写数据一定要写到本机房的限制,APP0会将DT1写到YZDC,APP1-3会将OT1-3写到TZDC,这个过程是不会损耗网络带宽的。但是如果DT1是一张基础表,往往有大量的下游任务依赖它,譬如这里APP1-3在会依赖DT1的数据产生OT1-3,这样就意为这存在3次跨机房读的过程。那么如何降低这些不必要的网络带宽呢?这里需要在TZDC部署HDFS1的数据节点,这里我们称为缓存节点。HDFS1会对指定目录设置策略,会将一部分副本拷贝到这些缓存节点上。这样APP1-3由于存在优先读本机房的限制,会读取缓存节点的副本,这样事实上只存在一次跨机房读的过程,大大降低了跨机房网络带宽。
3.2 跨机房HDFS集群的研发
前面介绍了跨机房集群对HDFS功能的基本需要,接下来主要介绍跨机房HDFS集群需要做的相关研发工作。
由于EC块的特点,这里多机房的功能不涉及到EC块。
3.2.1 机房策略
机房策略具体指副本在某个机房存放副本数的规则。对应于上一小节的问题分析,这里主要是为了将目录下的文件副本同步到其他将的缓存节点上。机房策略具体以xattr的形式存放在NameNode中,在NameNode切换的时候也可以实现快速恢复机房策略。机房策略具体的表示显示为DataCenterPolicy, 每个DataCenterPolicy会存储若干个DataCenterEntry,分别代表在某机房的具体策略,具体每个DataCenterEntry会以32个字节存放,其中0-7位记录机房名,8-23位记录副本数,高8位预留。下图即为策略在xattr存储的主要格式。其中DataCenterPolicy在DataCenterEntry外部会设置inherit继承为,用于控制策略的继承关系。
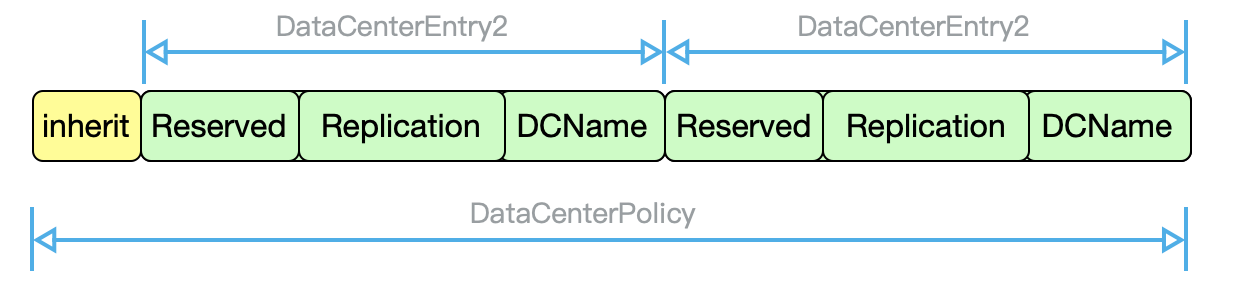
具体的我们将NameNode所在的机房将叫做PrimaryDC,其他机房叫MinorDC。我们主机房的副本数沿用HDFS文件的Replication,所以事实上只需其他机房的DataCenterEntry即可。因此,对于两个机房的场景下,只占用5个字节的存储空间。但是考虑尽可能地降低NameNode的元数据存储压力,这里提供了继承机制。我们强制指定只有在文件夹可以设置机房策略,同时如果文件或文件夹没有设置机房策略,会进一步查看父节点是否存在机房策略,会继承最近父亲节点的机房策略。同时可以通过inherit标志位控制策略。
关于机房策略的命令具体如下:
1 | 机房策略只可以由超级用户设置 |
下面讨论下关于机房策略的性能问题。考虑到xattr需要设置到INode内部,为了避免过大的Image文件,同时监控命令执行的速度,我们限制仅仅将机房策略设置到目录上。对于没有设置跨机房策略的INode,会依次读取器父目录是否存在跨机房策略,直到找到一个存在策略的目录或者找到根目录。实际的目录层级按照常理并不高,很难产生性能问题。同时由于是否确定某一个目录存在跨机房策略需要解析xattr,为了避免该步骤可能带来的性能影响,我们使用以空间换时间的方法,在目录级别加上是否存在机房策略的标志,在设置策略和加载fsimage和editlog会更新该标志位。这样大大地提高了获取机房策略的速度。而且,一般来讲NameNode的INodeDirectory的数量有限,带来的空间增长是可以接受的。通过实际的上线,相关的NameNode RpcProcessTime并没有发生明显的变化,也足够证明机房策略并没有引发性能问题。
3.2.2 跨机房场景的网络拓扑与副本选择
3.2.2.1 网络拓扑的改造
Hadoop官方代码没有考虑到机房这个维度。因此,在网络拓扑上的各个参数需要增加对网络机房信息的识别,因此需要定制化NetworkTopology等组件,按机房的维度统计机架、机器数目,选择机器等。这主要是为了后面实现自如的在跨机房间实现读写。具体有如下修改:
统计维度的方法修改,譬如需要统计机房的维度机架、机器数目等。
将默认从ROOT开始的拓扑遍历,修改为按机房遍历。
增加新的scope的规则。原有的chooseRandom中的scope的规则只有两个,即/dc1/rack1表示在/dc1/rack1下选择,~/dc1/rack1表示在/dc1/rack1之外选择。跨机房的场景,在兼容之前模式下,增加/dc1&~/dc1/rack1这样的scope,表示在dc1机房下,但不在/dc1/rack1机架上选择。
3.2.2.2 关于读数据
默认的Hadoop策略在读数据的时候,NameNode会返回每个数据块所有的位置信息,具体会按照与客户端的举例即可。因此,跨机房模式下,需要保证客户端获取的Location的顺序按照同机器、同机架、同机房、跨机房的顺序排序。这样尽可能避免跨机房读操作。具体做法是需要确保sortLocatedBlocks方法的准确性。
如果客户端节点在datanode上,则按照举例进行排序。会按照本机,同机架,同机房跨机架,跨机房的顺序进行排序。
如果客户端不在datanode节点上,namenode可以解析该节点的网络位置。也会按照本机,同机架,同机房跨机架,跨机房的顺序进行排序。
如果客户端不在datanode节点上,namenode不可以解析该节点的网络位置。原有的方案为按照可用性随机排序。跨机房方案需要修改为将dfs.local.dc.scope指示的机房节点排在前面。
3.2.2.3 关于写数据
需要保证一定要写到客户端所在的机房的DataNode。这里需要定制化BlockPlacementPolicy、chooseTarget等组件或方法识别机房信息实现只允许数据写到本机房中。
具体的实现主要是将chooseTarget以及其他相关函数增加dataCenter参数,通过该参数决定选择那个机房的副本。
如果客户端是DataNode节点。默认分配的三副本则为本机节点,同机房跨机架节点,与前两者某一个同机架的节点。同时按照与客户端所在DataNode节点的距离排序。
如果客户端是非DataNode节点,但是NameNode能够通过该节点的IP得到其机房机架地址。默认会在与客户端同机房生产三个副本,切分布在两个机架上。但是生产的排序与客户端的机房机架地址没有任何关系。
如果客户端是非DataNode节点,同时NameNode也不能通过该节点的IP得到其机房机架地址。默认会在dfs.primary.dc指示的机房生成三个副本,切分布在两个机架上。但是生产的排序与客户端的机房机架地址没有任何关系。
如果指定了favoredNodes, 如果其中某个favoredNode不是其所指定的默认机房,则不会在指定favoredNodes节点分配
对于ReplicationMonitor,需要让其识别机房维度的副本信息,并不断的查询具体哪个机房丢失副本或存在冗余副本。
3.2.3 跨机房副本拷贝与删除
3.2.3.1 跨机房副本拷贝与删除的基本原则
优先保证主机房的副本完整,其次保证跨机房的副本的完整性。
尽可能减少跨机房网络传输。触发拷贝操作的时候,只在本机房内拷贝。如果出现某个机房没有任何副本的时候,则必须要进行跨机房拷贝,默认值只允许跨机房拷贝一个副本。
如果客户端在副机房上,则将副本写到副机房。然后ReplicationMonitor会在后台将他转换为正常的副本分布。
3.2.3.2 跨机房副本拷贝与删除的原理
我们先来看看HDFS数据块删与拷贝的基本原理。限于篇幅和表达的原因,这里只介绍了部分流程,下图只并且强调解释过程,实际存储可能与代码详情略有出入,望谅解。首先是块拷贝的主要流程。一般有checReplication(一般写文件调用complete方法或commit方法且副本达到最低要求等过程会调用)或块汇报等等诸多过程会触发副本检查。如果检查发现需要复制,则加入到needReplications列表中,当然这里的检查要修改为支持多机房副本的检查。ReplicationMonitor以一个线程的方式存在,他会定期检查有那些需要块需要复制,根据控制参数和机房机架副本的确实情况以及上一个小节描述的规则会产生ReplicationWork,每个RepliationWork会根据当前设置的BlockPlacementPolicy找到要复制的数据块。然后会将要复制的信息放入到对应DataNodeDescriptor结构体中,等待心跳发送给DataNode。同时也会写入到pendignReplication中,用于处理拷贝异常或超时等情况,以便于处理复制失败的情况。对于跨机房集群,我们需要对这个过程做多机房场景的适配,以不断满足文件在不同机房的不同副本要求。
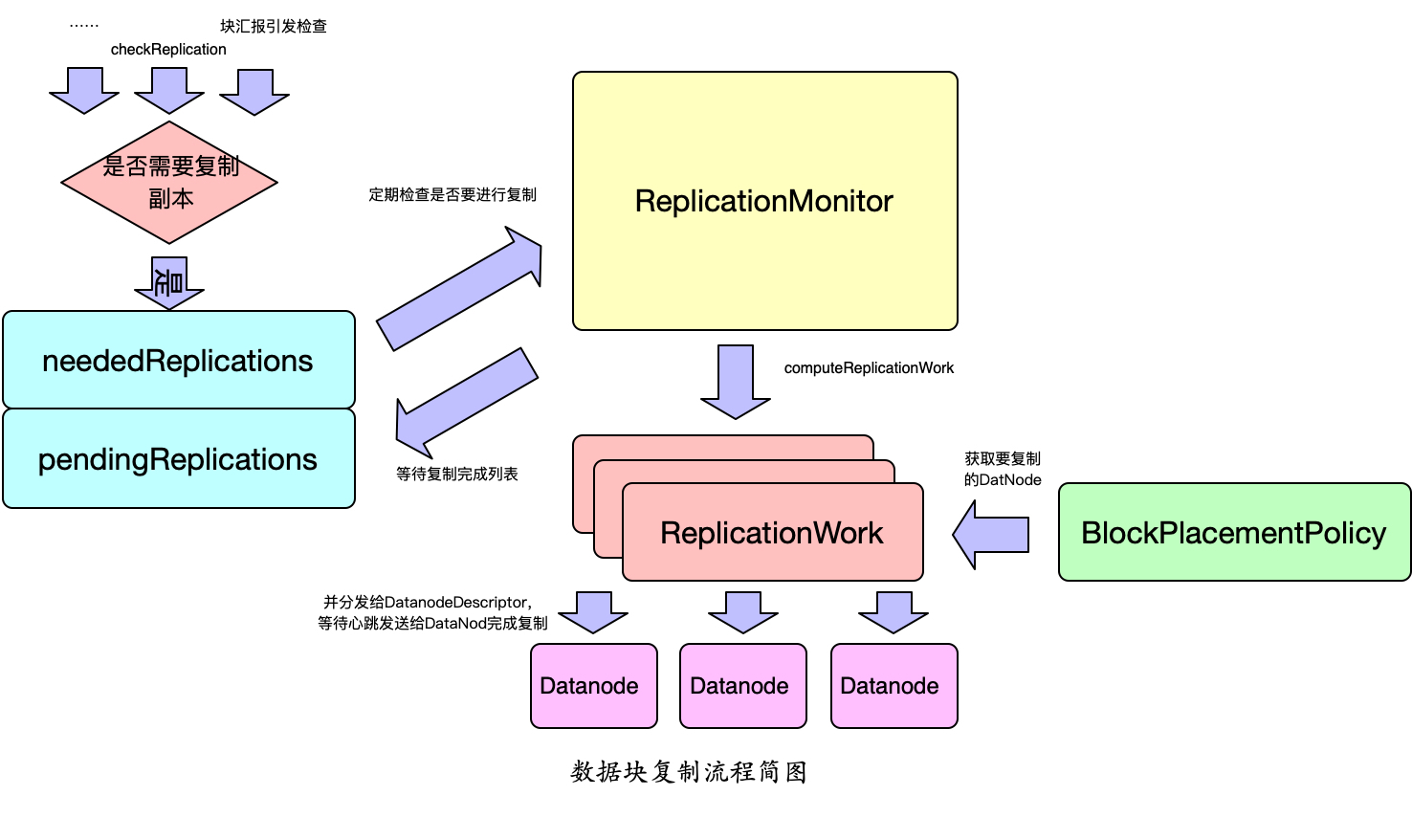
对于删除数据块的要求,会略有不同,但基本流程大致类似。这里就不在详细介绍了。
3.2.4 DataCenterPolicyHook
由于新产生的目录往往不存在策略。为了保证机房策略尽快生效,我们需要一种方法快速对新产生的目录上设置机房策略。显然外部的组件是很难满足这样的要求的。因此,我们在NameNode端增加了DataCenterPolicyHook的机制,快速对mkdir和rename操作产生或移动的新目录设置策略。
3.2.5 DCMover
关于跨机房策略生效,对于增量的文件数据可以通过hook等方式,可以确保文件写完成的时候就能使跨机房策略生效。但是对于存量数据,则无法保证这一点。EC policy或HDFS Storage Policy也存在同样的问题的,他们是通过Mover组件来实现策略的生效。对于跨机房策略实施略有不同,我们可以通过DCMover组件来使存量数据进行生效,DCMover组件会检查一次检查文件策略,根据实际的副本数通过replaceBlock方法进行策略生效。
由于集群可能出现下线等操作,大量的块复制情况可能会阻塞ReplicationMonitor发送的跨机房的ReplicatonWorker。为了保证跨机房副本快速同步到缓存节点而不影响任务速度,我们改造了Mover组件为DCMoverd组件。DCMoverd作为一个辅助同步组件,支持机房维度的数据再均衡,会不断地读取Editlog的信息,发现有要设置的文件新创建,会立刻触发检查机房副本并将数据按照设置的策略进行拷贝。
3.2.6 其他
对于balancer和mover,我们也需要对齐进行多机房维度的改造,需要限制其仅仅在同机房的数据节点进行拷贝。
4 数据搬迁
4.1 RBF
在Hadoop集群搬迁的过程中,为了实现“尽可能降低在项目实施过程中的用户接入成本”的目标,RBF启动了关键的作用。这里首先会简单介绍一下RBF的功能。
4.1.1 RBF功能概述
Hadoop社区在Hadoop-2.x提供了Hadoop Federation的功能。但是随着集群规模的不断增加,集群的性能依旧受限于文件数、节点数、DataNode节点的心跳以及来自客户端的RPC请求。同时Hadoop Federation不利于集群管理员对存储资源和配置进行有效的调度。在Hadoop-3.x提供了RBF功能(Router-based Federation),即基于HDFS Router的Federation。如下图所示,HDFS集群会整体划分为多个SubCluster,通过HDFS Router组件对客户端提供服务。各个HDFS Router组件通过存储于StateStore中的映射表实现路径映射,实现一套完成的名称空间。如下图所示,客户端端会访问SubCluster0的HDFS Router,HDFS Router会根据存储于StateStore中的映射表找到数据路径对应的子集群SubCluster1,然后Router会将客户端的请求转发给SubCluster1的NameNode。
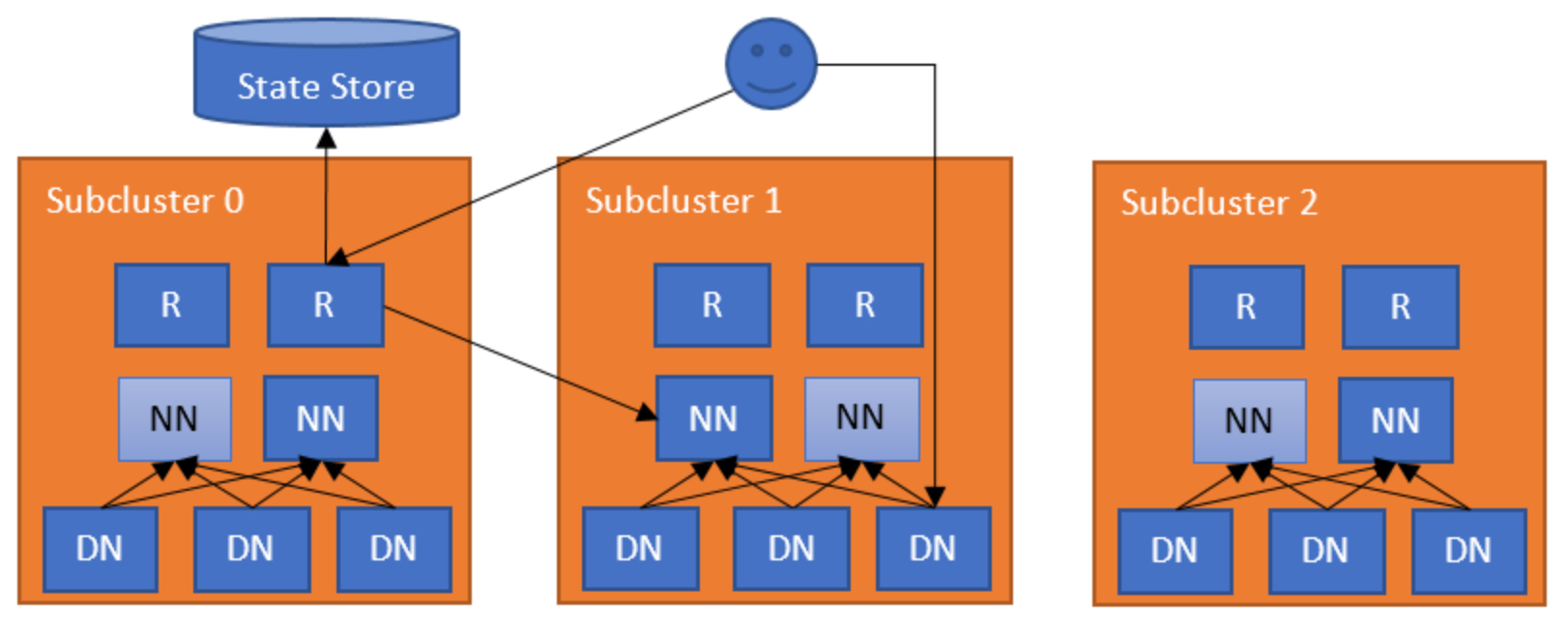
HDFS RBF的维护了完整统一的数据视角,可以完全对用户屏蔽具体的集群概念,发据迁移过程中我们只需修改State Store中的Moutable表的内容即可让用户无感知地完成迁移。HDFS RBF,同时也大大提高了集群规模的的上线。
4.1.2 映射规则
HDFS Mountable实际是以树的形式存储于DFSRouter中。如果找不到路径对应的Key,会找到小于该Key的集合中最近的Key。假如,我们定义了/user/bigdata的nameservice为ns6,/user/bigdata/a.db的nameservice为ns5。对于/user/bigdata/a.db我们会将请求转发给ns5,对于/user/bigdata/b.db由于没有设置对应的Mountable,会转向其父目录/user/bigdata对应的nameservice,即ns6。
RBF存在多种映射规则,对于单个NameService映射规则意义不大,挂载单NameService的规则我们统一使用默认的HASH。
RBF同时支持单个路径可以对应多个NameService的功能,同时匹配各种规则。譬如,SPACE规则可以让一个路径指向多个NameService。假设/user/bigdata使用SPACE规则,并指向ns5和ns6,当写数据到/user/bigdata的时候,会优先选择存储多的nameservice以写入。对于遍历目录的时候,DFSRouter会同时读取ns5和ns6的目录。对于读文件的时候,DFSRouter依旧会读取所有nameservice,哪个nameservice存在便会读取哪个nameservice的文件。如果两个nameservice都存在,则按照映射规则选择优先的namservice读取。或者这个时候你会问这里会不会出现不一致的问题,事实上RBF的设计者认为由于始终使用DFSRouter,写文件是不会写两份的,因此理论上也不会存在在两个nameservice下存在同一个文件的问题。不过这个在我们的搬迁场景是一个例外,后面后着重分析这个问题。
4.1.3 效率
关于RBF的效率的问题。DFSRouter节点会在内存中维护当前最新的Mountable表的信息。每次修改Mountable表的时候,首先会将表信息加载到Zookeeper的StateStore,然后会通知所有DFSRouter从StateStore全量加载最新的Mountable表到内存中。这样保证了一致性,也保证了DFSRouter的性能。尽管Mountable是以树的结构存储于DFSRouter的内存中,但是考虑到Mountable不断膨胀可能会引发性能问题,再加之其带来的管理成本,我们在实际生产过程中是严格控制Mountable的数量的。
4.1.4 定制化研发
Hadoop-3.2.1并没有Release一个完整的RBF功能,仍然存在很多问题。具体如下:
Hadoop-3.2.1版本的RBF并不支持Kerberos认证功能。这部分功能主要是紧跟社区的脚步,支持了该功能。
映射表无法立即生效的问题。这个我们通过HDFS-15198解决了该问题。
Hadoop-3.2.1版本的RBF不能兼容Hadoop-2.7.3的HDFS集群。由于我们集群部署中设计到Hadoop-3.2.1版本的DFSRouter管理Hadoop-2.7.3版本的HDFS,所以涉及到很多的API不兼容的问题。这里我们也一一解释所有问题了。
RBF场景下无法获取优先HDFS客户端IP。跨机房HDFS集群需要根据IP获取机房信息,因此这个问题是我们项目必须要解决的。我们在HADOOP-16254的基础上修改了相关代码实现了该功能的支持。
4.2 数据迁移方案
介绍该迁移流程之前,我们介绍方案可能会需要的映射规则。其中这里有一种新型的Moutable规则,FIXED OERDER(由于后来发现其他公司在相关分享中也有类似的方案,因此我们也统一了使用该命名)。FIXED ORDER实际就是指定将选取优先的nameservice固定为指定的nameservice,我们称为fixed nameservice。即写数据会优先写到fixed nameservice。

数据迁移的流程大致如下:
初始业务目录使用Hash Order(nn-cluster),表示该目录仅仅指向nn-cluster一个namservice,如图(a)所示。
我们修改该业务目录的策略为Fixed Order(nn-cluster:fixed, ns3),如图(b)所示。预先挂载双目录的主要目的是避免同步数据与拷贝存量同时发生造成数据不一致。
启动DataMigration同步任务,将在旧集群的存量数据同步到新集群中。(事实上该不做的主要目的是预先在新集群上创建目录,保证RBF模式下可以正常rename。)
我们修改该业务目录的策略为Fixed Order(nn-cluster, ns3:fixed),此后新写的数据将全部写入到新集群,如果(c)所示所示。
同时也将计算任务切换到新集群中。
再次启动DataMigration同步任务,将在旧集群的增量数据同步到新集群中。
待100%的数据完全迁移到新集群,我们将该业务目录的策略修改为Hash Order(ns3)。这样就完成了完整的数据迁移。
该方案是在业务无感知的情况下完成的平滑的数据迁移。
4.2.3 数据同步工具的研发
传统的数据迁移工作,需要配人工管理多组distcp任务。往往需要大量的人力资源,有时候甚至是一个小团队的资源。
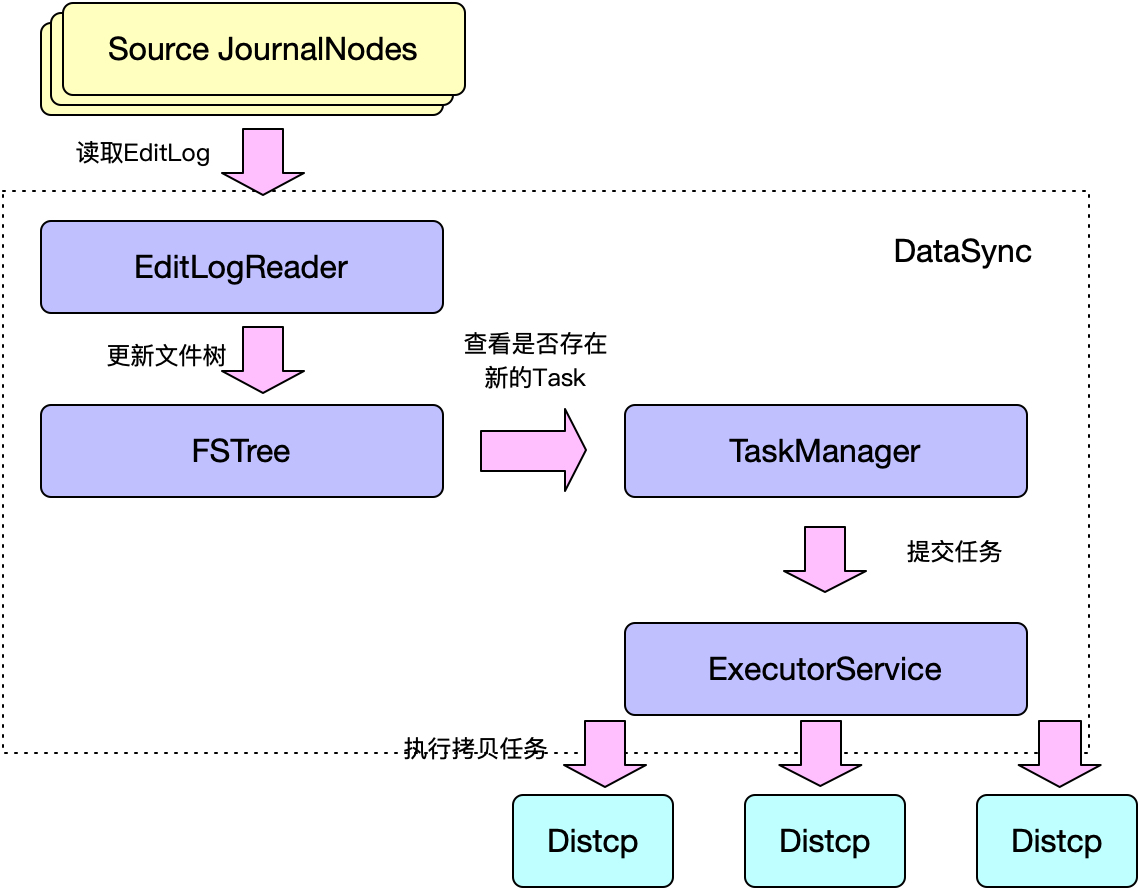
为了减少人力资源,这里开发了DataSync组件。对要迁移的业务目录组织成文件树FSTree,TreeNode具体会记录某一个文件更新的情况。我们以某个要迁移的目录下的N级子目录作为一个Task进行任务迁移。TaskManger是主控程序,会定期读取FSTree查看是否有新的Task生成,同时也会检查是否有Task达到了进行拷贝的条件,即提交到ExecutorService来实现自动化的数据拷贝。同时DataSync也支持抓取NameNode的EditLog的功能,可用于快速触发同步新产生的数据。
4.2.4 一致性
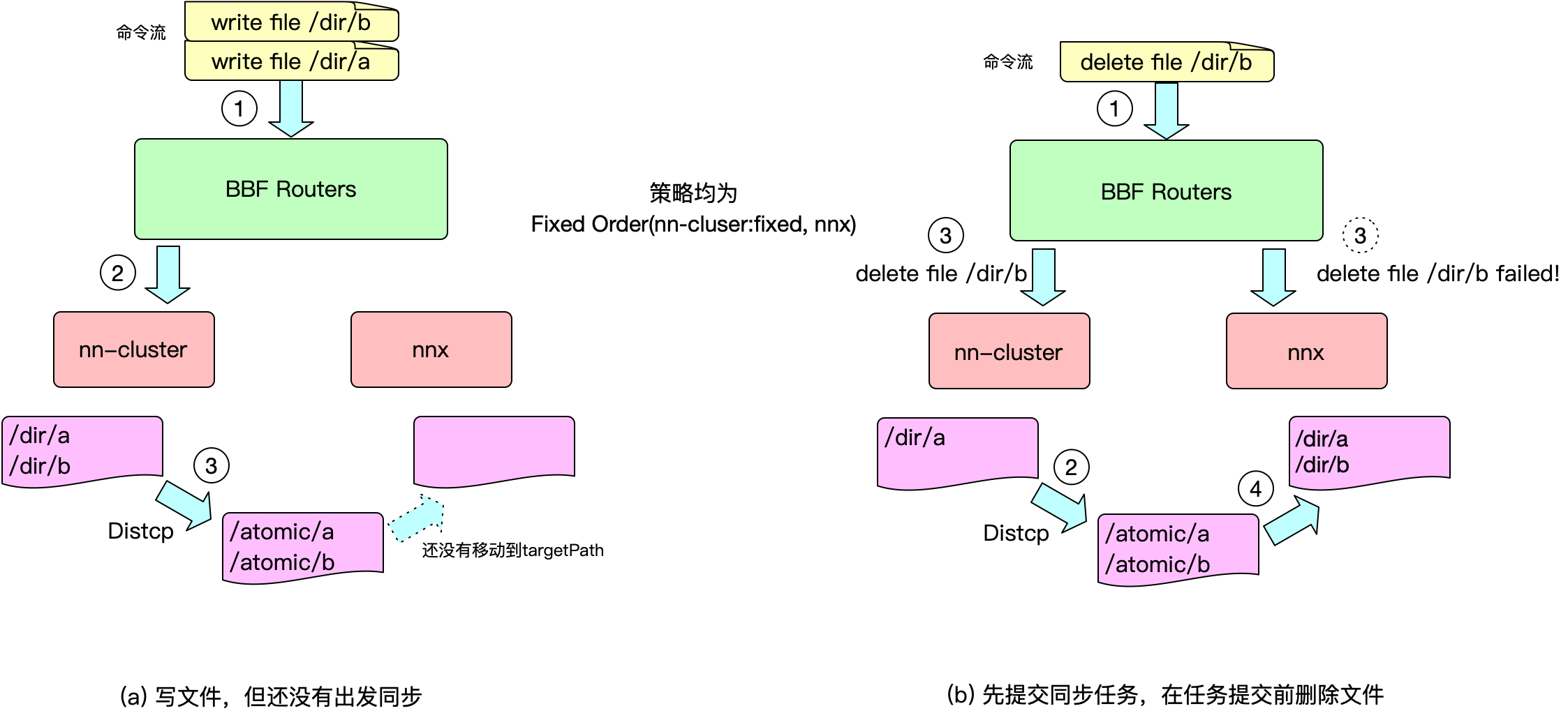
如果再数据同步过程中出现了删除数据怎么办呢?假如当前的策略为FixedOrder(nn-cluser:fixed, nnx)。客户端通过DFSRouter发起写⽂件/dir/a和/dir/b的请求,DFSRouter会将请求转发到nn-cluster,nn-cluster会创建两个⽂件。如果这个时候提交distcp任务,distcp任务会提交遍历源目录,确认拷贝/dir/a和/dir/b。但是当将/dir/b拷贝到nnx的/atomic/b目录后,如果出现了删除/dir/b的操作,nn-cluster2会正常除,但是nnx会因为数据完全没有同步过来⽽放弃这个删除操作,然后会将/atomic/b重命名到/dir/b。这样从用户视角上/dir/b并没有删除,会造成数据的不⼀致。
我们设计了checksrcexist参数解决这个问题。开启该参数后,distcp会每次rename⽂件后,会检查源是否存在,如果存在会删掉这个⽂件。数据迁移的过程可以理解为将源集群的editlog到新集群上回放的过程,因为这是⼀个异步的过程,存在删除的操作的情况下,是很难做到完全的数据⼀致的。由于NameNode Rpc是的操作时间最⾼不超过ms级别,出现该问题的记录是极低的。通过checksrcexist,我们也将出现不⼀致的时间降低到毫秒级别。因此,该问题不会对业务产⽣影响。
如果在数据同步过程中出现了譬如append等修改操作,也可能会出现不⼀致的情况。假如该append的⽂件还没有提交到新的NameService,会在旧集群进⾏append操作。⽂件在append真正执⾏之前提交到新集群,然后在旧⽂件执⾏append操作,这样就会出现不⼀致的情况,这里我们通过checksrcsame选项在追后进⾏检查,如果出现这种问题即执⾏删除该⽂件,置任务失败。
4.3 总结
我们通过该技术⽅案⼤⼤地降低了搬迁的成功,原则上对于⼤部分用户不需要修改⼀⾏代码即可完成数据迁移。


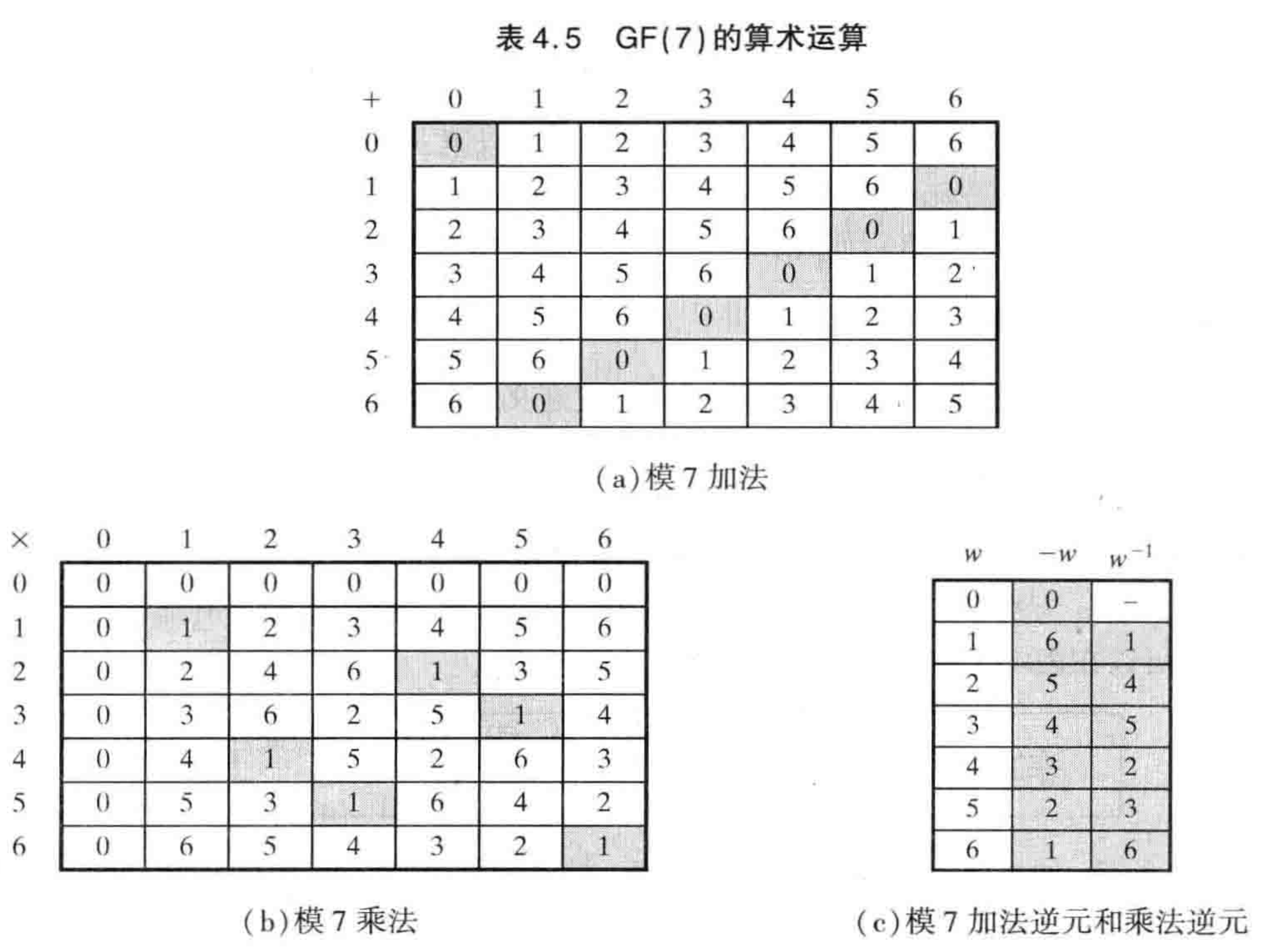
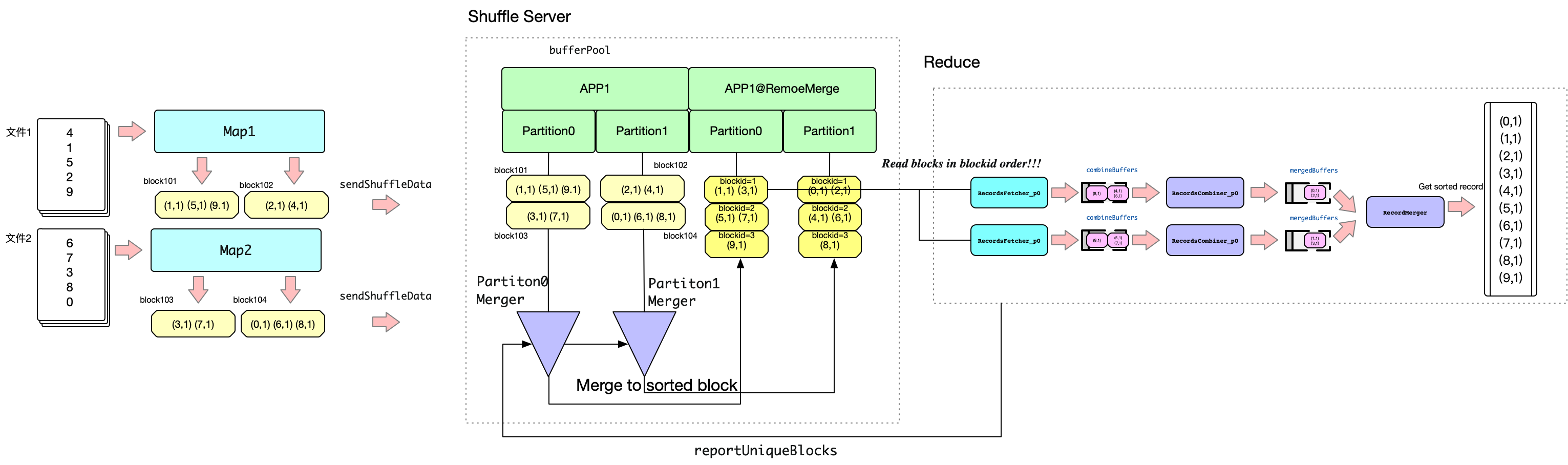
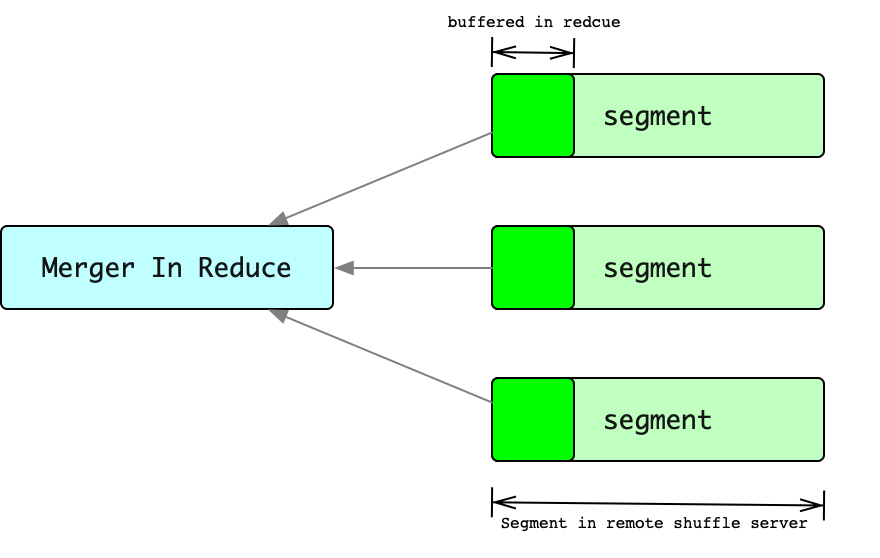 Since the memory on the reduce side is limited, in order to avoid spilling data to disk when merging on the reduce side. When reduce obtains segment, it can only read part of the buffer of each segment, and then merge all the buffers. Then when the partial buffer reading of a certain segment is completed, the next buffer of this segment will continue to be read, and this buffer will continue to be added to the merge process.
There is a problem with this. The number of times the Reduce side reads data from ShuffleServer is approximately segments_num * (segment_size / buffer_size), which is a large value for large tasks. Too many RPCs means decreased performance.
Since the memory on the reduce side is limited, in order to avoid spilling data to disk when merging on the reduce side. When reduce obtains segment, it can only read part of the buffer of each segment, and then merge all the buffers. Then when the partial buffer reading of a certain segment is completed, the next buffer of this segment will continue to be read, and this buffer will continue to be added to the merge process.
There is a problem with this. The number of times the Reduce side reads data from ShuffleServer is approximately segments_num * (segment_size / buffer_size), which is a large value for large tasks. Too many RPCs means decreased performance.