支持向量机(SVM)
1 Margins(间隔)
对于一个逻辑回归问题,\(p(y = 1|x, \theta )\)可以通过下面的式子表示:
$${h _ \theta }(x) = g({\theta ^T}x)$$\(\theta^Tx\)越大, \(g({\theta ^T}x)\)就越大, 我们就有可高的信心认为\(y=1\)。 同理假如\({ h _\theta }(x) << 0\), 我们就有很强的信息认为\(y=0\)。 (注: >> 表示远大于,<<表示远小于)
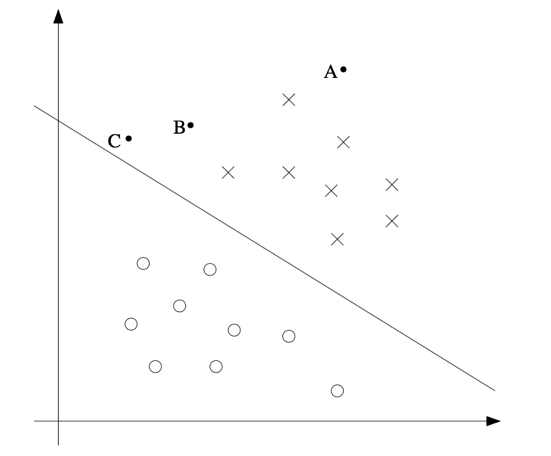
上面这张图,x为正样本,o为负样本。中间的直线是分割超平面。上面图中,我们可以知道对于样本A,我们有很强的信心认为\(y=1\)。然后对于C却接近边界,如果稍微改变分割超平面,就可能导致\(y=0\)。因此,越远离分割超平面的样本,我们越有信息获得他的分类。
2 函数化与几何间隔
区别与之前的逻辑回归。引入支持向量机,我们需要重新定义符号。对于SVM问题, \(y \in \{ - 1,1\} \),定义函数为:
$${h_{w,b}}(x) = g({w^T}x + b)$$对于\(z = {w^T}x + b > 0\), 有\({h _ \theta }(x) = 1\)。 否则\({h _ \theta }(x) = -1\)。
函数化几何间隔,有如下公式:
$${\hat \gamma ^{(i)}} = {y^{(i)}}({w^T}x + b)$$上式很容易理解,对于正样本\(y=1\),对于负样本\(y=-1\)。因此可以得到\({\hat \gamma ^{(i)}}\)为一个正值。我们可以就可以定义其为几何间隔,可以理解为距离。根据上一节的分析,一个超平面对样本分割的好坏,取决于距离超平面最近的样本。因为我们定义最小间隔如下:
$$\hat \gamma = {\min _{i = 1,...,m}}{\hat \gamma ^{(i)}}$$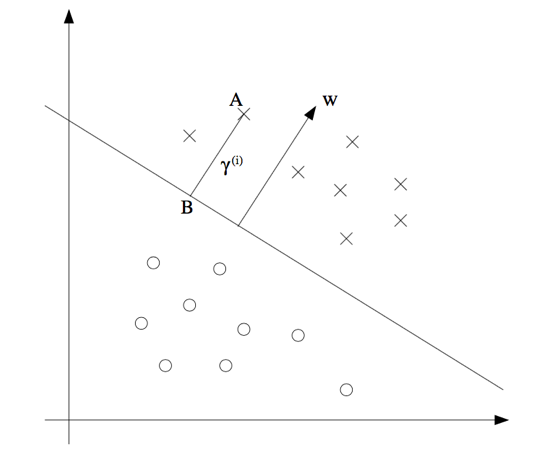
根据上图,我们知道向量\(w\)与超平面\({w^T}x + b = 0\)垂直。
在超平面找任意两点做直线,易证其与法向量內积为零。因此可知法向量与平面垂直。
我们可以得知B点的坐标为\({x^{(i)}} - {r^{(i)}}\frac{w}{||w||}\),我们将坐标代入超平面方程,有:
$${w^T}({x^{(i)}} - {r^{(i)}}\frac{w}{||w||}) + b = 0$$由于知道\(||w|| = {w^T}w\),有:
$${r^{(i)}} = {(\frac{w}{||w||})^T}{x^{(i)}} + \frac{b}{||w||}$$上面公式对应于正样本,对于负样本则需要加一个符号。因此我们可以综合得到如下公式:
$${r^{(i)}} = {y^{(i)}}({(\frac{w}{||w||})^T}{x^{(i)}} + \frac{b}{||w||})$$对于公式\({\hat \gamma ^{(i)}} = {y^{(i)}}({w^T}x + b)\)中,\(||w|| = 1\)的时候为几何间隔。上面的式子实际上就是定义了几何间隔。我们通过定义了向量\(w\)的尺度,这样不会因为选择w比例的不同而产生不同间隔的问题。
3 最优间隔分类器
以下假定我们样本数据是严格线性可分的,否则通过间隔最大化来计算就毫无意义了。
根据前面的分析,我们只需要找到超平面,使得间隔\(\hat \gamma \)最大即可。因此我们可以得到如下最优化问题:
$$\begin{gathered} & {\max _{w,b}}\gamma \hfill \\\ s.t.: & {y^{(i)}}({w^T}{x^{(i)}} + b) \geqslant \gamma , & i = 1,...,m \hfill \\\ & ||w|| = 1 \hfill \\\ \end{gathered} $$由于\(||w|| - 1 = 0\)不是凸函数,所以需要转化问题。
注> 为什么凸函数如此重要?因为对于一个凸优化问题,认为局部极小值点必为全局极小值点。对\(f(\lambda x + (1 - \lambda )y) \leqslant \lambda f(x) + (1 - \lambda )f(y)\),其中\(0 \leqslant \lambda \leqslant 1\),则\(f(x)\)为凸函数。可以理解为类似于\(y = {x^2}\)的图形。然而对于\(||w|| - 1 = 0\),具体为\(\sqrt {w _1^2 + w _2^2 + … + w _n^2} = 1\),二维的情景可以理解为一个圆,三维的话则为一个球。几何图形中,可以发现对于球或圆的上半部分正好与凸函数相反,因此不是凸函数。可以代入公式证明。
进一步转化问题,如下:
我们知道\(\gamma \)大小,取决于\(w\)和\(b\)的尺度,但是\(w\)和\(b\)的尺度的改变不会影响分配效果。因此我们固定\(\gamma \)为1。将问题转化为:
$$\begin{gathered} & {\min _{w,b}}\frac{1}{2}||w|{|^2} \hfill \\ s.t.: & {y^{(i)}}({w^T}{x^{(i)}} + b) \geqslant 1, & i = 1,...,m \hfill \\ \end{gathered}$$事实上对于这个问题,我们可以换一种几何意义的解释。如下图所示,我们需要找到\({w^T}x + b = 1\)和\({w^T}x + b = -1\)能够有效分割样本,并且保证是两个超平面之间间隔最大,即使\(\frac{2}{||w||}\)最大,也就意味着使\(\frac{1}{2}||w|{|^2}\)最小。同样我们可以得到上面的优化问题。
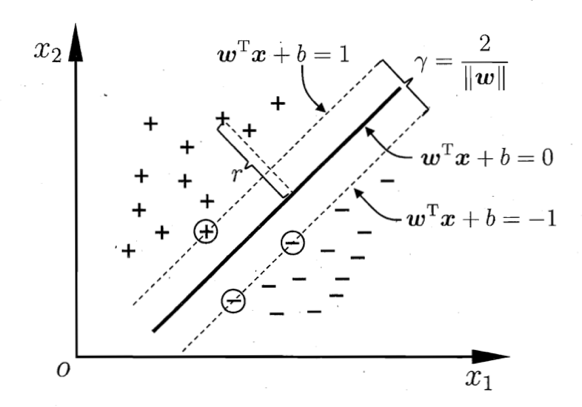
另外,我们距离超平面最近的点,即\(\gamma = 1\)的点,我们称之为支持向量。
4 拉格朗日对偶问题
在对计算上一级得到的优化问题之前,我们介绍一下拉格朗日对偶问题与KKT条件,以便于更容易解决问题。考虑一个通用的优化问题,如下:
$$\begin{gathered} & {\min _x}f(x) \hfill \\\ s.t.: & {g _i}(x) \leqslant 0, & i = 1,...,k \hfill \\\ & {h _j}(x) = 0, & j = 1,...,l \hfill \\\ \end{gathered} $$然后得到拉格朗日函数,如下:
$$L(x,\alpha ,\beta ) = f(x) + \sum\limits _{i = 1}^k {{\alpha _i}{g _i}(x)} + \sum\limits _{j = 1}^l {{\beta _i}{h _i}(x)} $$ $${\alpha _i} \geqslant 0$$对于我们的原始问题如何用拉格朗日函数表达呢?我们知道上面的拉格朗日后面两项的最大值为零。因此我们就可以将原始问题转化为以\({\alpha _i}\)和\({\beta _i}\)为参数情况下,求拉格朗日函数的最大值。具体转化为如下形式:
$${\theta _P}(x) = {\max _{\alpha ,\beta ;{\alpha _i} \geqslant 0}}L(x,\alpha ,\beta )$$然后我们上面的式子,关于x取极小值,就与目标问题一致了。原始为的最优解最终可以通过如下方式表述:
$${p^*} = {\min _x}{\theta _P}(x) = {\min _x}{\max _{\alpha ,\beta ;{\alpha _i} \geqslant 0}}L(x,\alpha ,\beta )$$我们这里可以写出其对偶问题:
$${\theta _D}(\alpha ,\beta ) = {\min _x}L(x,\alpha ,\beta )$$对偶问题的最优解如下:
$${d^*} = {\max _{\alpha ,\beta ;{\alpha _i} \geqslant 0}}{\theta _D}(\alpha ,\beta ) = {\max _{\alpha ,\beta ;{\alpha _i} \geqslant 0}}{\min _x}L(x,\alpha ,\beta )$$我们知道maxmin<minmax,所以我们得到如下式子:
$${d^*} = {\max _{\alpha ,\beta ;{\alpha _i} \geqslant 0}}{\min _x}L(x,\alpha ,\beta ) \leqslant {\min _x}{\max _{\alpha ,\beta ;{\alpha _i} \geqslant 0}}L(x,\alpha ,\beta ) = {p^\*}$$对于上面的式子只要\(f _i\)和\(g _i\)为凸函数,\(h _i\)为仿射函数,即可使等式两端相等。
$$\frac{\partial }{{\partial {x _i}}}L({x^*},{\alpha^*},{\beta^*}) = 0$$ $$\frac{\partial }{{\partial \beta }}L({x^*},{\alpha ^*},{\beta ^*}) = 0$$ $${\alpha ^*}{g _i}(x) = 0$$ $${g _i}(x) \leqslant 0$$ $${\alpha ^*} \geqslant 0$$仿射函数为线性函数加截距。
另外对于该问题的最优值必满足KKT条件。另外,上述拉格朗日函数对相应参数需要取得极值。最终得到如下条件:
KKT条件的原理暂时不深入,目前处于应用阶段,有时间再考虑具体原理。
5 最优边界分类器
将我们的优化问题转化为如下标准型:
$$\begin{gathered} & {\min _{w,b}}\frac{1}{2}||w|{|^2} \hfill \\\ s.t.: & - {y^{(i)}}({w^T}{x^{(i)}} + b) + 1 \leqslant 0, & i = 1,...,n \hfill \\\ \end{gathered} $$根据前面的说明,我们可以通过解对偶问题最优解来获得该问题的最优解。
首先写出拉格朗日对偶函数:
参数上一节的公式,这里\(w\)和\(b\)对应于\(x\)。我们需要关于\(w\),\(b\)求极小值,然后求得的极值点代入拉格朗日函数,然后求转化后的拉格朗日函数的极大值即可。
$$\frac{\partial }{{\partial w}}L(w,b,\alpha ) = w - \sum\limits _{i = 1}^m {{\alpha _i}{y^{(i)}}{x^{(i)}}} = 0$$ $$\frac{\partial }{{\partial b}}L(w,b,\alpha ) = \sum\limits _{i = 1}^m {{\alpha _i}{y^{(i)}}} = 0$$得到\(w = \sum\limits _{i = 1}^m {\alpha _i}{y^{(i)}{x^{(i)}}} \),\(\sum\limits _{i = 1}^m {\alpha _i}{y^{(i)}} = 0\)。然后将其代入拉格朗日函数:
$$L(\alpha ) = \frac{1}{2}{w^T}w - \sum\limits _{i = 1}^m {{\alpha _i}({y^{(i)}}({w^T}{x^{(i)}} + b) - 1)} $$ $$L(\alpha ) = - \frac{1}{2}{(\sum\limits _{i = 1}^m {{\alpha _i}{y^{(i)}}{x^{(i)}}} )^T}(\sum\limits _{i = 1}^m {{\alpha _i}{y^{(i)}}{x^{(i)}}} ) + \sum\limits _{i = 1}^m {{\alpha _i}} $$由于\({\alpha _i}\)和\({y^{(i)}}\)为变量,实际上面的式子就是一个\((Ax + By + Cz)(Ax + By + Cz)\)的问题。因此可以归纳为如下公式:
$$L(\alpha ) = - \frac{1}{2}\sum\limits _{i = 1}^m {\sum\limits _{j = 1}^m {{\alpha _i}{\alpha _j}{y^{(i)}}{y^{(j)}} < {x^{(i)}},{x^{(j)}} > } } + \sum\limits _{i = 1}^m {{\alpha _i}} $$问题就转化为:
$$\begin{gathered} & {\max _\alpha }L(\alpha ) = - \frac{1}{2}\sum\limits _{i = 1}^m {\sum\limits _{j = 1}^m {{\alpha _i}{\alpha _j}{y^{(i)}}{y^{(j)}} < {x^{(i)}},{x^{(j)}} > } } + \sum\limits _{i = 1}^m {{\alpha _i}} \hfill \\\ s.t.: & {\alpha _i} \geqslant 0 \hfill \\\ & \sum\limits _{i = 1}^n {{\alpha _i}{y^{(i)}}} = 0 \hfill \\\ \end{gathered} $$由于我们知道支持向量的间隔必须为1,因此我们可以根据其计算\(b\)。设支持向量的集合为S,对属于结合S的样本有\({y^{(i)}}({w^T}{x^{(i)}} + b) = 1\)。由于\(w = \sum\limits _{i = 1}^m {\alpha _i}{y^{(i)}}{x^{(i)}} \),又由于对所有的非支持向量,有\({\alpha _i} = 0\)。因此我们可以综合均值得到:
$$b = \frac{1}{{|S|}}\sum\limits _{i = 1}^S {({y^{(i)}} - \sum\limits _{j = 1}^S {{\alpha _j}{y^{(j)}} < {x^{(i)}},{x^{(j)}} > } )} $$6 正则化
关于之前的问题我们假定样本严格可分。但是实际上需要容忍一些误差。因此我们将公式修正为如下形式(C为常数):
$$\begin{gathered} & {\min _{w,b,\xi }}\frac{1}{2}||w|{|^2} + C\sum\limits _{i = 1}^m {{\xi _i}} \hfill \\\ s.t.: & {y^{(i)}}({w^T}{x^{(i)}} + b) \geqslant 1 - {\xi _i} & & i = 1,...,m \hfill \\\ & {\xi _i} \geqslant 0 & & & & i = 1,...,m \hfill \\\ \end{gathered} $$我们允许\({y^{(i)}}({w^T}{x^{(i)}} + b)\)小于1,但是不希望小太多。所以,我们需要保证\({\xi _i}\)的总和尽可能小,因此得上面的式子。然后我们可以得到拉格朗日公式如下:
$$L(w,b,\xi ,\alpha ,r) = \frac{1}{2}||w|{|^2} + C\sum\limits _{i = 1}^m {{\xi _i}} - \sum\limits _{i = 1}^m {{\alpha _i}({y^{(i)}}({w^T}{x^{(i)}} + b) - 1 + {\xi _i})} - \sum\limits _{i = 1}^m {{r _i}{\xi _i}} $$对\(w\),\(b\),\(\xi \), 求导得:
$$\frac{\partial }{{\partial w}}L(w,b,\xi ,\alpha ,r) = w - \sum\limits _{i = 1}^m {{\alpha _i}{y^{(i)}}{x^{(i)}}} = 0$$ $$\frac{\partial }{{\partial b}}L(w,b,\xi ,\alpha ,r) = - \sum\limits _{i = 1}^m {{\alpha _i}{y^{(i)}}} = 0$$ $$\frac{\partial }{{\partial {\xi _i}}}L(w,b,\xi ,\alpha ,r) = C - {r _i} - {\alpha _i} = 0$$可以得到\(w = \sum\limits _{i = 1}^m {\alpha _i}{y^{(i)}}{x^{(i)}}\),\(\sum\limits _{i = 1}^m {\alpha _i}{y^{(i)}} = 0\),\(C = {r _i} + {\alpha _i}\)。其中我们知道\({r _i} \geqslant 0\),所以也可得到\(0 \leqslant {\alpha _i} \leqslant C\)。带入拉格朗日函数得:
$$L(\alpha ) = - \frac{1}{2}\sum\limits _{i = 1}^m {\sum\limits _{j = 1}^m {{\alpha _i}{\alpha _j}{y^{(i)}}{y^{(j)}} < {x^{(i)}},{x^{(j)}} > } } + \sum\limits _{i = 1}^m {({r _i} + {\alpha _i}){\xi _i}} - \sum\limits _{i = 1}^m {{\alpha _i}({\xi _i}} - 1) - \sum\limits _{i = 1}^m {{r _i}{\xi _i}} $$我们对上面的式子乘以-1,转化为求最小值的问题,可以得到最终的优化问题:
$$\begin{gathered} & \min L(\alpha ) = \min \frac{1}{2}\sum\limits _{i = 1}^m {\sum\limits _{j = 1}^m {{\alpha _i}{\alpha _j}{y^{(i)}}{y^{(j)}} < {x^{(i)}},{x^{(j)}} > } } - \sum\limits _{i = 1}^m {{\alpha _i}} \hfill \\\ s.t.: & \sum\limits _{i = 1}^m {{\alpha _i}{y^{(i)}}} = 0 \hfill \\\ & 0 \leqslant {\alpha _i} \leqslant C \hfill \\\ \end{gathered} $$可以得到如下的KKT条件:
$${\alpha _i},{r _i} \geqslant 0$$ $${y^{(i)}}({w^T}{x^{(i)}} + b) - 1 + {\xi _i} \geqslant 0$$ $${\alpha _i}({y^{(i)}}({w^T}{x^{(i)}} + b) - 1 + {\xi _i}) = 0$$ $${\xi _i} \geqslant 0,{r _i}{\xi _i} = 0$$对于上述KKT条件我们可以转换为如下形式:
$${y^{(i)}}({w^T}{x^{(i)}} + b) \geqslant 1 , {\alpha _i} = 0$$ $${y^{(i)}}({w^T}{x^{(i)}} + b) \leqslant 1 , {\alpha _i} = C$$ $${y^{(i)}}({w^T}{x^{(i)}} + b) = 1 , 0 \leqslant {\alpha _i} \leqslant C$$很容易转化上面的式子,三个条件分别表示在比支持向量距离分割超平面远的样本,比支持向量距离分割超平面近的可容忍的误差样本,支持向量对应的样本。
7 SMO算法理论
这一节使用SMO算法解决上一节归纳出来的优化问题。
SMO算法的思想来自于坐标上升算法,坐标上升算法的主要思想是一次遍历一个变量,然后把其他变量当做是常亮,进在一个维度上优化。
然后对于我们之前的问题,有\(\sum\limits _{i = 1}^m {\alpha _i}{y^{(i)}} = 0\)。设置我们设\(\zeta = {\alpha _1}{y^{(1)}} + {\alpha _2}{y^{(2)}} = \sum\limits _{i = 3}^m {\alpha _i}{y^{(i)}} \),将\({\alpha _1}\)用\({\alpha _2}\)表达,然后得到关于\({\alpha _2}\)的二次函数,这样很容易取得极值。当所有样本满足KKT条件,且无法继续增加,我们就可以认为此刻取得最优值。
由于我们知道\(0 \leqslant {\alpha _i} \leqslant C\),所以我们可以求的其取值范围,我们可以将二维变量表述为一个方格内,具体如下:
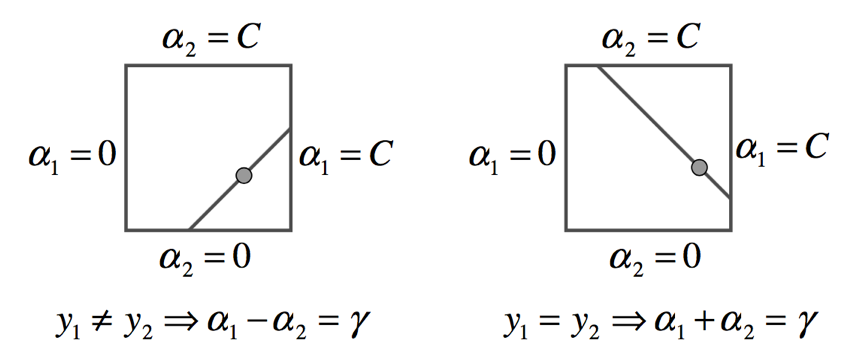
最多四种情况代入,经过求截距等一系列操作,可以将的取值范围归纳为下面的公式,其中L表示上界,H表示上界。
同号时有:
异号的时候有:
$$L = \max (0,\alpha _2^{old} - \alpha _2^{old})$$ $$H = \min (C,C + \alpha _2^{old} - \alpha _1^{old})$$进一步求解二次规划问题:
$$\psi ({\alpha _1},{\alpha _2}) = \frac{1}{2}\alpha _1^2k(1,1) + \frac{1}{2}\alpha _2^2k(2,2) + {y^{(1)}}{y^{(2)}}{\alpha _1}{\alpha _2}k(1,2) - {\alpha _1} - {\alpha _2} + {y^{(1)}}{\alpha _1}{v _1} + {y^{(2)}}{\alpha _2}{v _2} + M$$上式中\(k(i,j) = < {x _i},{x _j} > \)具体是核函数的简写,下节会介绍。\(M\)为与\(\alpha _1\),\(\alpha _2\)无关的参数。另外,\({v _1} = \sum\limits _{i = 3}^m {\alpha _i}{y^{(i)}}k(1,i) \),\({v _2} = \sum\limits _{i = 3}^m {\alpha _i}{y^{(i)}}k(2,i) \)。
我们设\(\zeta = {\alpha _1}{y^{(1)}} + {\alpha _2}{y^{(2)}}\),所以有\({\alpha _1} = {y^{(1)}}(\zeta - {\alpha _2}{y^{(2)}})\),代入上式:
$$\psi ({\alpha _2}) = \frac{1}{2}{(\zeta - {\alpha _2}{y^{(2)}})^2}k(1,1) + \frac{1}{2}\alpha _2^2k(2,2) + {y^{(2)}}(\zeta - {\alpha _2}{y^{(2)}}){\alpha _2}k(1,2) - (\zeta - {\alpha _2}{y^{(2)}}){y^{(1)}} - {\alpha _2} + (\zeta - {\alpha _2}{y^{(2)}}){v _1} + {y^{(2)}}{\alpha _2}{v _2} + M$$然后求导数:
$$\frac{\partial }{{\partial {\alpha _2}}}\psi ({\alpha _2}) = ({\alpha _2}{y^{(2)}} - \zeta ){y^{(2)}}k(1,1) + {\alpha _2}k(2,2) + {y^{(2)}}\zeta k(1,2) - 2{\alpha _2}k(1,2) + {y^{(1)}}{y^{(2)}} - {y^{(1)}}{y^{(2)}} - {y^{(2)}}{v _1} + {y^{(2)}}{v _2} = 0$$ $$\frac{\partial }{{\partial {\alpha _2}}}\psi ({\alpha _2}) = {\alpha _2}(k(1,1) + k(1,2) - 2k(1,2)) - \zeta {y^{(2)}}k(1,1) + \zeta {y^{(2)}}k(1,2) + {y^{(1)}}{y^{(2)}} - {y^{(1)}}{y^{(2)}} - {y^{(1)}}{v _1} + {y^{(2)}}{v _2} = 0$$我们设\(\eta = k(1,1) + k(1,2) - 2k(1,2)\),对\(\eta\)大于0的情况,导数为0的极值点就是极小值。对于\(\eta\)小于等于0的情况,最小值点肯定取自于边界,我们需要比较函数在\(L\)和\(H\)的大小。
让我们继续简化上面的式子,对于\(\eta\)大于0的情况下,取得极值。由于我们轻易得到下面的关系。
$${v_1} = \sum\limits _{i = 1}^m {{\alpha _i}{y^{(2)}}k(1,i)} + b - b - \sum\limits _{i = 1}^2 {{\alpha _i}{y^{(2)}}k(1,i)} = f({x^{(1)}}) - b - \sum\limits _{i = 1}^2 {{\alpha _i}{y^{(2)}}k(1,i)} $$ $${v_2} = \sum\limits _{i = 1}^m {{\alpha _i}{y^{(2)}}k(2,i)} + b - b - \sum\limits _{i = 1}^2 {{\alpha _i}{y^{(2)}}k(2,i)} = f({x^{(2)}}) - b - \sum\limits _{i = 1}^2 {{\alpha _i}{y^{(2)}}k(2,i)} $$将上面的关系代入的如下极值:
$$\alpha _2^{new} = \frac{{\zeta {y^{(2)}}k(1,1) - \zeta {y^{(2)}}k(1,2) + {y^{(2)}}({y^{(1)}} - f({x^{(1)}}) - ({y^{(2)}} - f({x^{(2)}})) - {y^{(2)}}\sum\limits _{i = 1}^2 {\alpha _i^{old}{y^{(2)}}k(1,i)} + {y^{(2)}}\sum\limits _{i = 1}^2 {\alpha _i^{old}{y^{(2)}}k(2,i)} }}{\eta }$$我们将\(\zeta = {\alpha _1}{y^{(1)}} + {\alpha _2}{y^{(2)}}\)代入上式,得:
$$\alpha _2^{new} = \frac{{{\alpha _1}{y^{(1)}}{y^{(2)}}k(1,1) + {\alpha _2}k(1,1) - {\alpha _1}{y^{(1)}}{y^{(2)}}k(1,2) - {\alpha _2}k(1,2) - {\alpha _1}{y^{(1)}}{y^{(2)}}k(1,1) - {\alpha _2}k(1,2) + {\alpha _2}{y^{(1)}}{y^{(2)}}k(1,2) + {\alpha _2}k(2,2) + {y^{(2)}}({y^{(1)}} - f({x^{(1)}}) - ({y^{(2)}} - f({x^{(2)}}))}}{\eta }$$约掉部分选项,有:
$$\alpha _2^{new} = \alpha _2^{old} + \frac{{{y^{(2)}}({y^{(1)}} - f({x^{(1)}}) - ({y^{(2)}} - f({x^{(2)}})))}}{\eta }$$ $$\alpha _2^{new} = \alpha _2^{old} + \frac{{{y^{(2)}}({e _1} - {e _2})}}{\eta }$$接下来就只剩下求\(b\)的问题了,根据上一节最后转化的KKT条件。对\(0 \leqslant {\alpha _1} \leqslant C\)的情况下,有\({y^{(1)}}({w^T}{x^{(1)}} + b) = 1\)。所以有:
$$b = {y^{(1)}} - \sum\limits _{i = 1}^m {{\alpha _i}} {y^{(i)}}k(1,i)$$进一步展开有:
$$b = {y^{(1)}} - \sum\limits _{i = 3}^m {\alpha _i^{new}{y^{(i)}}k(1,i)} - \alpha _1^{new}{y^{(1)}}k(1,1) - \alpha _2^{new}{y^{(2)}}k(1,2)$$我们知道上面的式子中\({\alpha _3}\)到\({\alpha _m}\)并没有发生变化,因此有:
$$\sum\limits _{i = 3}^m {\alpha _i^{new}{y^{(i)}}k(1,i)} = \sum\limits _{i = 3}^m {\alpha _i^{old}{y^{(i)}}k(1,i)} = \sum\limits _{i = 1}^m {\alpha _i^{old}{y^{(i)}}k(1,i)} - \alpha _1^{old}{y^{(1)}}k(1,1) - \alpha _2^{old}{y^{(2)}}k(1,2) = f({x^{(1)}}) - b - \alpha _1^{old}{y^{(1)}}k(1,1) - \alpha _2^{old}{y^{(2)}}k(1,2)$$代入如上式得:
$${b^{new}} = - {e_1} + (\alpha _1^{old} - \alpha _1^{new}){y^{(1)}}k(1,1) + (\alpha _1^{old} - \alpha _1^{new}){y^{(2)}}k(1,2) + {b^{old}}$$对于\({\alpha _2}\)有同样的道理。
综上,假如\(0 \leqslant {\alpha _1} \leqslant C\),有:
$${b^{new}} = - {e_1} + (\alpha _1^{old} - \alpha _1^{new}){y^{(1)}}k(1,1) + (\alpha _1^{old} - \alpha _1^{new}){y^{(2)}}k(1,2) + {b^{old}}$$假如\(0 \leqslant {\alpha _2} \leqslant C\),有:
$${b^{new}} = - {e_2} + (\alpha _2^{old} - \alpha _2^{new}){y^{(1)}}k(2,1) + (\alpha _2^{old} - \alpha _2^{new}){y^{(2)}}k(2,2) + {b^{old}}$$假如\(0 \leqslant {\alpha _1},{\alpha _2} \leqslant C\),事实上上面两个公司的出来的结果是一样的,因此不用特殊计算。
如果不满足在\(0\)和\(C\)的范围,则去两个公式的中间值。(笔者认为没有必要更新)
8 SMO算法实践
在SMO论文中有具体的伪代码,算法的主要逻辑就是要保证每个样本都满足KKT条件,且直到所有\(\alpha \)达到极值,即不需要更新为止。
然后是关于\(\alpha \)的选择,第一个\(\alpha \)我们可以随机选择一个违反KKT条件的,第二个我们选择能够最大程度更新\(\alpha \)的值,看上一节的公式,实际会选择\(|e _1-e _2|\)最大的样本点作为第二个\(\alpha \)。具体逻辑可以参考SMO的论文,或者下面代码的注释。代码如下:
1 | import numpy as np |
经过数轮迭代得到如下结果,其中直线为得到的分割曲线,蓝色点为支持向量,红色点是那些有良好分类的样本,绿色点为可容忍的误差样本。
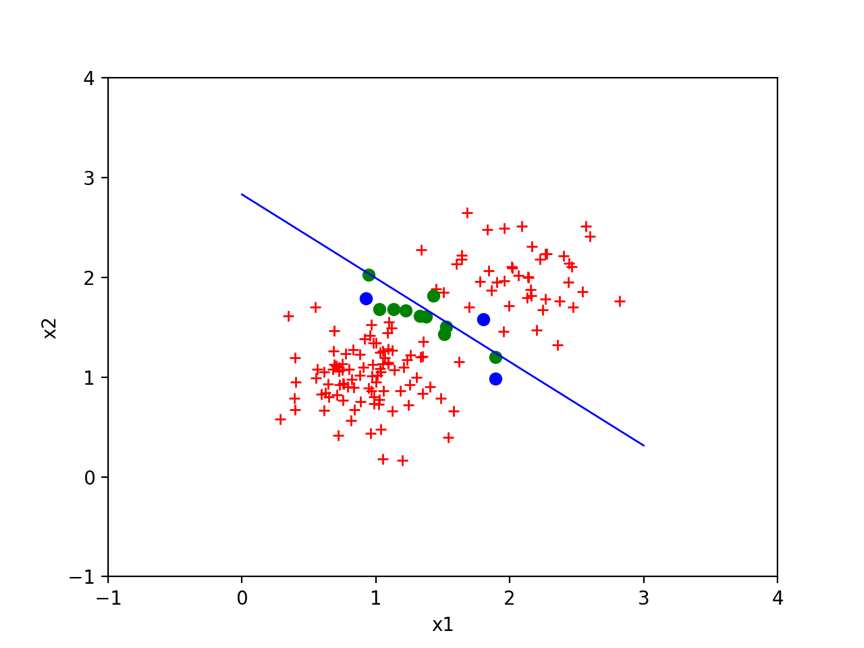
9 核函数
SMO另个非常强大的地方上,它能够很好的解决非线性问题。我们之前的公式中有\(<{x _i},{x _j}>\),他是两个向量的內积,代表着两个样本的相关性。我们把这个叫做核函数。核函数不仅仅是可以为简单的內积,还可以对样本进行多维展开,映射到高维地址空间。这样在低维地址空间线性不可分的样本,在高维空间就变得线性可分了。譬如,\(|x| < 1\)不是线性可分的,但是对其进行\(x \to (x,{x^2})\)映射后,也就的到一个二次曲线,我们可以使用\(y = 1\)进行线性分割。
下面直接引入高斯核函数,它可以对函数进行无线维空间的映射。具体定义如下:
$$k(x,z) = \exp ( - \frac{{||x - z|{|^2}}}{{2{\sigma ^2}}})$$对于核函数的数学理论和几何意义,以及高斯核为啥可以向无限维空间映射,之后有时间需要详细研究。
我们制造一组\(x _1^2 + x _2^2 = 1\)分割的样本,然后尝试对其进行分割,实际上与上一节程序的区别仅仅在于核函数的选取,这里我们使用高斯核函数。
1 | import numpy as np |
经过数轮迭代之后,得到参数。然后在随机产生一些样本,通过训练集得到参数对随机测试样本进行分割,结果如下,发现分割效果还是很理想的。
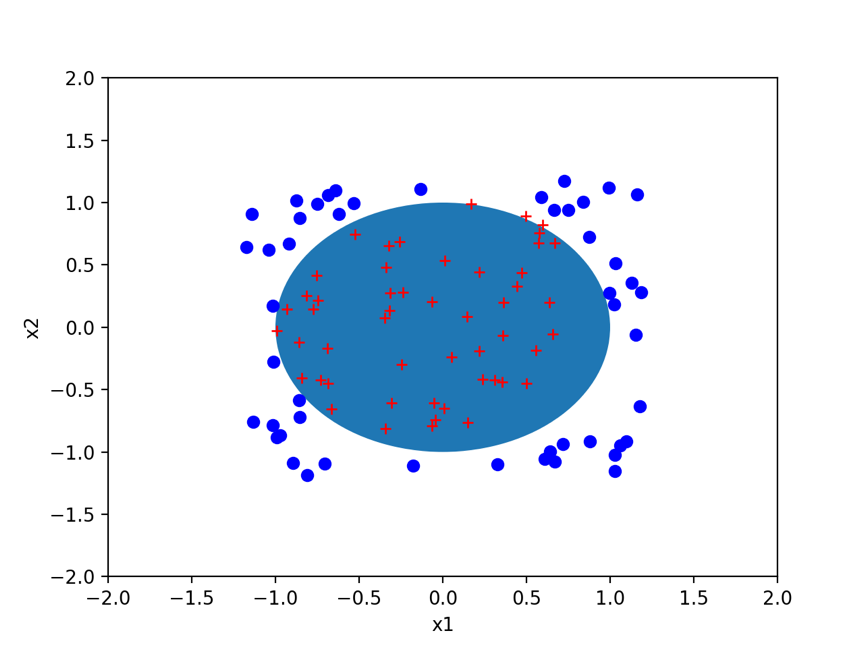
附录
手写公式和word版博客地址:
1 | https://github.com/zhengchenyu/MyBlog/tree/master/doc/mlearning/支持向量机 |
参考文献
- cs229-notes3
- 机器学习 周志华版
- Fast Training of Support Vector Machines Using Sequential Minimal Optimization
- http://blog.csdn.net/luoshixian099/article/details/51227754