主成分分析(PCA)
严格上说PCA应该算是一种降低维度的方法,这里暂时归类为非监督学习中。
1 PCA理论简述
PCA的主要思路是将\(n\)维数据降维到\(k\)维子空间中,以滤除不需要的噪声或没有意义的特征信息。譬如我们有汽车的一组运行数据,包括专项半径、速度等。其中就一个用英里/每小时和千米/每小时描述的速度,很明显两者是呈线性关系的,只是因为舍入带来一些误差,对于这样的问题我们完全可以将这个\(n\)维数据移到\(n-1\)维子空间中。
再举一个例子,对于RC直升机驾驶员的调查,\(x _1\)表示飞行员驾驶技能,\(x _2\)表示他对驾驶直升飞机的爱好程度。因为RC直升机很难驾驶,因此我们可以认为只有任务对驾驶RC直升机感兴趣的驾驶员才能学好它。因此,\(x _1\)和\(x _2\)有强相关性。如下图所示,我们可以假定一个方向\(u _1\),用来表示\(x _1\)和\(x _2\)两个属性,仅仅在其垂直轴\(u _2\)上有少量噪声。
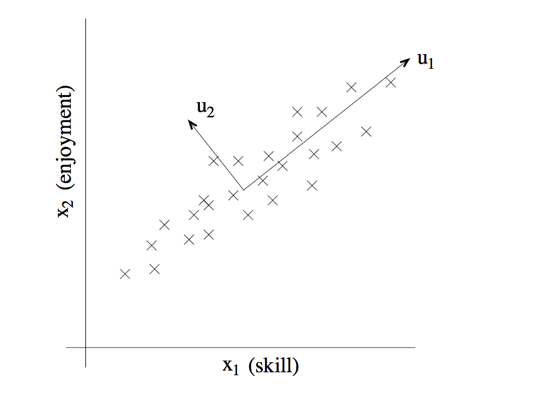
对数据降维之前,我们需要对数据进行初始化,主要是一个归整的过程,将均值归整为0,将方差归整为1。依次按照如下公式进行归整。
- \(\mu = \frac{1}{m}\sum\limits _{i = 1}^m {x^{(i)}} \)
- \({x^{(i)}}: = {x^{(i)}} - \mu \)
- \({\sigma ^2} = \frac{1}{m}\sum\limits _{i = 1}^m {(x^{(i)})^2} \)
- \({x^{(i)}}: = {x^{(i)}}/\sigma \)
归整后的数据如下,可以知道如果\(x\)在向量\(u\)的投影最大。说明\(u\)在对\(x _1\)和\(x _2\)的降维过程中带来的损失越小。
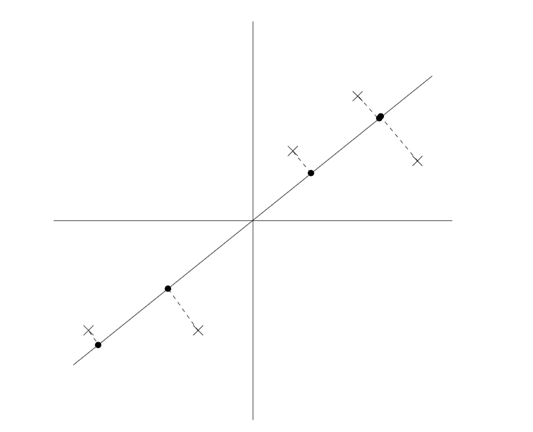
因此,可以需要保证下式最大:
$$\frac{1}{m}\sum\limits _{i = 1}^m {{{({x^{{{(i)}^T}}}u)}^2}} = \frac{1}{m}\sum\limits _{i = 1}^m {{u^T}{x^{(i)}}{x^{{{(i)}^T}}}u} = {u^T}(\frac{1}{m}\sum\limits _{i = 1}^m {{x^{(i)}}{x^{{{(i)}^T}}}} )u$$问题也就转变为找到一组\(u\)使得,上式最大的问题。然后我们假定\(u\)为一组标准正交基,因此\(||u||=1\)。因此问题可写为如下形式:
$$\begin{gathered} & \max {u^T}(\frac{1}{m}\sum\limits _{i = 1}^m {{x^{(i)}}{x^{{{(i)}^T}}}} )u \hfill \\\ s.t.: & ||u|| = 1 \hfill \\\ \end{gathered} $$组成其拉格朗日函数如下:
$$L(u,\lambda ) = {u^T}(\frac{1}{m}\sum\limits _{i = 1}^m {x^{(i)}x^{(i)^T}} )u - \lambda (||u|| - 1)$$这里我们设\(\Sigma=\frac{1}{m}\sum\limits _{i = 1}^m {x^{(i)}{x^{(i)^T}}}\),然后对\(u\)求导数,易得:
$${\nabla _u}L(u,\lambda ) = \sum u - \lambda u = 0$$因此,我们知道\(\lambda\)为\(\Sigma\)的特征值,\(u\)为对应的特征向量。恰好为我们要求的向量\(u\)。得到一组新的正交基后,我们就可以映射到新的空间中了。具体如下:
$${y^{(i)}} = {(u _1^T{x^{(i)}},u _2^T{x^{(i)}},...,u _k^T{x^{(i)}})^T}$$2. PCA的奇异值分解
由于一般为\(n*n\)的维度,因此往往是一个很大的矩阵。对于维度很大,样本数目要少于维度很多的数据,这样计算往往有不够划算。因此我们可以通过求解\(x\)的特征值的方法来求节\(\Sigma\)的特征向量。
由于求矩阵的单位特征向量,可以不考虑1/m这个系数。
假如对\(x\)进行奇异值分解,其中\(U\)和\(V\)均为酉阵,\(\Lambda\)为对角阵。另外值得注意的是酉阵的可逆矩阵与转置矩阵相同。具体分解形式如下:
$$x = U\Lambda {V^T}$$因此可以得到:
$$\Sigma = x{x^T} = U\Lambda {V^T}V\Lambda {U^T} = U{\Lambda ^2}{U^T}$$ $$\Sigma U = {\Lambda ^2}{U^T}$$因此可以知道\(\Sigma\)的特征向量对应着\(x\)的奇异值分解中的\(U\)。同时\(\Sigma\)的特征值为\(x\)的奇异值的平方。
3 源码实现
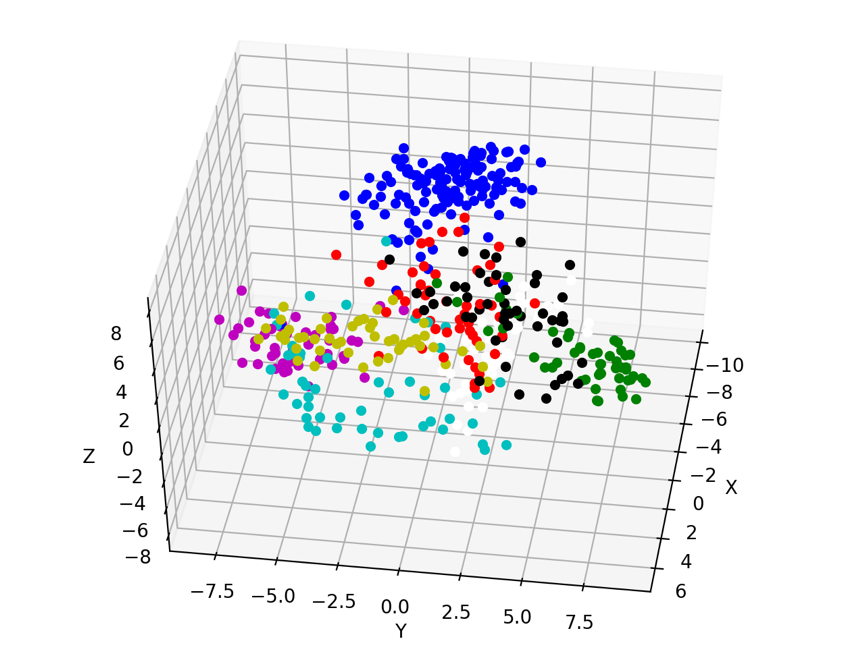
我们对k临近算法中的手写数字识别做分析。我们首先对数字映射到三维空间中,然后进行展示。然后在映射到样本数量维度的空间,实现对数字的识别。值得一提是,PCA可以将多种无法直接展示的多维数组转化为三维数据,然后更直观地进行分析。
1 | import numpy as np |
500个测试样本中,有27个识别错误,具体识别率为94.6%。这与未使用PCA降维的完全一致。该例子似乎尚未体现到PCA有什么优势,以后有机会在分析。当然如果映射到三维空间,识别率仅仅为75.2%,因此不要过度降维。下面是一个展示到部分数据的三维图。
考虑到颜色,图片只显示部分类别数据。
4 参考文献
- cs229-note10
- 机器学习实战