1 默认的shuffle
注: 第一节简单介绍了主流框架默认的shuffle的原理,目的为了那里会使用本地磁盘,从而设计远程Merge。如果足够了解,可以忽略这部分内容。
我们依次对MapReduce, Tez, Spark的shuffle进行分析。
1.1 MapReduce
Map将Record写入到内存,当内存超过阈值的时候,会将内存的数据spill到磁盘文件中,按照partitionid+key的顺序依次将Record写入到磁盘文件。当Map处理完所有Record后, 会将当前内存中的数据spill到磁盘文件。然后读取所有的spill到磁盘的文件,并按照partitionid+key的顺序进行merge,得到排序的Records。
注: 按照partitionid排序的目的是Reduce端从Map端获取的数据的时候,尽可能顺序读。对于MR、Tez、Spark, 无论是否排序,只要有分区,都需要按照partitionid进行排序。
Reduce端会从Map端以远程或本地的方式拉取对应分区的Records,称之为MapOutput。正常情况下会直接使用内存,如果内存超过阈值会将这些Records写入到磁盘。然后Reduce端会对所有MapOutput使用最小堆K路归并排序进行一些Merge操作,得到全局排序的Reccords。Merge的过程中,可能会因为内存超过阈值,会将临时的结果spill到磁盘。另外如果spill到磁盘的文件过多,也会触发额外的merge。
1.2 Tez
Tez的情况略微复杂。Tez分为ordered io和unordered io。
ordered io与MapReduce相同,不再展开分析。
unordered io一般用于hashjoin等不需要key进行排序的情况。非排序的io采用来之即用方案。Map直接将Record写入文件或者通过缓存在写入文件。Reduce端也是读数据的时候也是读之即用。
1.3 Spark
spark的shuffle更复杂,也更合理。部分任务是不需要sort和combine的,因此spark用户可以需求决定shuffle的逻辑。
1.3.1 Shuffle写操作
写shuffle数据的时候,支持三种writer:
- (1) BypassMergeSortShuffleWriter
为每个partition都生成一个临时文件。在写Record的时候,找到对应的分区直接写入对应的临时文件。然后当所有数据都处理完成后,将这些临时的文件按照分区的顺序依次写入到一个最终的文件,并删除临时文件。
- (2) UnsafeShuffleWriter
UnsafeShuffleWriter主要通过ShuffleExternalSorter来实现具体的逻辑。当写Record的时候,直接序列化操作,并将序列化的字节拷贝到申请的内存中。同时也会将Record的地址和分区记录到内存中(inMemSorter)。
当内存的Record达到阈值的时候,会进行spill操作。根据内存(inMemSorter)中的信息,我们很容易得到一个按照分区排序的Record,并写到文件中。
当处理完所有Record,我们会把当前内存中的Records spill到文件中。最后对所有spilled文件进行一次聚合。由于之前spilled的文件已经是按照分区排序的,所以我们可以按照分区的顺序依次将所有spill的文件的对应自己拷贝到最终文件。这样得到的最终文件即为分区排序的文件。
- (3) SortShuffleWriter
SortShuffleWriter主要通过ExternalSorter来实现具体逻辑。ExternalSorter根据用户的需求决定是否combine和sort。
当写Record的时候,会直接插入到内存中。如果需要combine,内存架构是map,否则是buffer。
如果当前评估内存大于阈值会触发spill操作。spill操作的时候,会将Record,然后spill到磁盘。这个过程是需要进行排序的。而具体的比较器会根据用户需求的不同使用不同的值。如果设置了keyordering会按照key进行排序。如果没有设置keyordering,但是设置了aggregator(即combine),则按照key的hashcode进行排序,这样保证相同的key组织一起,便于combine操作。如果keyordering和aggregator都没有设置,则会按照partiton进行排序。
所有Record都写完时,需要读取spill的文件,并合并成一个全局有序的文件。
三种writer的比较
| writer | 优点 | 缺点 | 场景 |
|---|---|---|---|
| BypassMergeSortShuffleWriter | (1) 只经过一次序列化。 (2) 采用类hashmap的数据结构,插入数据快。 |
(1) 不支持combine (2) 每个分区都要对应生成一个临时文件,会产生过多的临时文件。 |
适合分区数较少(默认小于等于200)且没有combine的的情况. |
| UnsafeShuffleWriter | (1) 只经过一次序列化。 (2) spill到磁盘的文件数目有限,不再基于分区数,可以支持更大的分区。 |
(1) 不支持combine (2) 写入顺序Record顺序会打乱,要求supportsRelocationOfSerializedObjects。 |
适用于没有combine的情况,且支持supportsRelocationOfSerializedObjects,并且支持最大支持分区数为16777216。 |
| SortShuffleWriter | (1) 支持combine (2) 适合于所有场景 (3) spill到磁盘的文件数目有限 |
(1) 需要进行多次序列化 | 适用于所有场景。 |
1.3.2 shuffle读
当前只有BlockStoreShuffleReader一个实现。实现与MapReduce类似。
Reduce端会从Map端以远程或本地的方式拉取对应分区的Records。正常情况下会直接写到内存中,但如果要获取的block大小超过阈值则会使用磁盘。
然后会根据用户的需求决定是否进行combine或sort,最终形成一个用户要求的record iterator。
combine和sort分别使用了ExternalAppendOnlyMap和ExternalSorter,当内存超过阈值后,会将数据spill到本地磁盘中。
1.4 总结
(1) 关于各个框架语义
对于MapReduce和Tez的ordered io, 实质就是spark的排序的特例。对于Tez的unordered io,实质上就是spark的非排序的特例。实质各个框架上语义是相同的, spark更加泛化。
(2) 哪里会产生本地磁盘文件?
分析三种计算框架后,我们得知如下过程会使用磁盘:
- (1) Map由于内存超越阈值,可能会产生中间的临时文件。
- (2) Map端最终必然会产生磁盘文件,用于提供shuffle服务。
- (3) Reduce拉取records时候,可能因为超越阈值,产生磁盘文件。
- (4) Reduce端Merge的时候,可能会产生临时的磁盘文件,用于全局排序。
而事实上, uniffle已经解决(1), (2)。对于(3), 如果有效的调整参数,是很难产生磁盘文件的。事实上只有(4)是本文需要讨论的。
2 方案的选择
为了解决在Reduce端Merge可能会spill到磁盘的问题,主要有两个方案:
- (1) Shuffle Server端进行Merge
- (2) Reduce端按需Merge
2.1 方案1: ShuffleServer端进行Merge
将Reduce的Merge过程移到ShuffleServer端,ShuffleServer会对Map端发来的局部排序后的Records进行Merge,合并成一个全局排序的Records序列。Reduce端直接按照哦Records序列的顺序读取。
- 优点: 不需要过多内存和网络RPC。
- 缺点: Shuffle Server端需要解析Key, Value和Comparator。Shuffle端不能combine。
2.2 方案2: Reduce端按需Merge
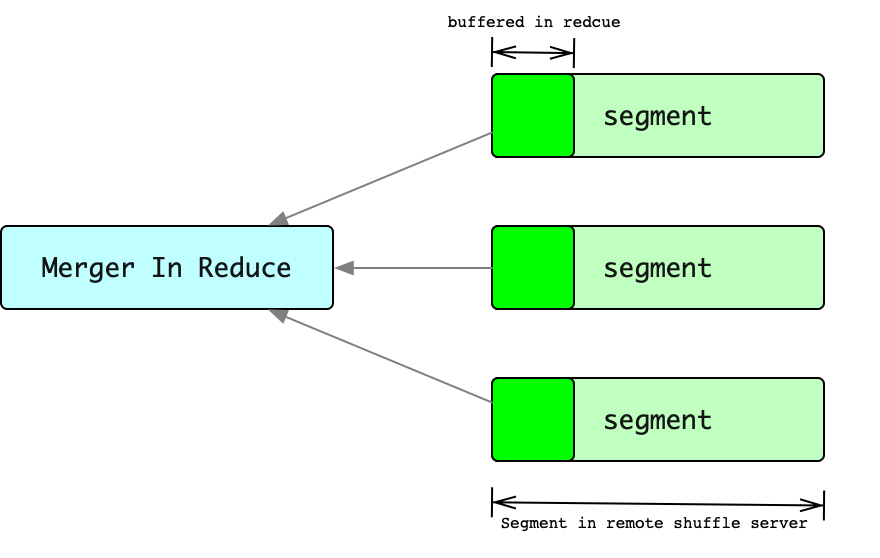 由于Reduce端内存有限,为了避免在Reduce端进行Merge的时候spill数据到磁盘。Reduce在获取Segment只能读取每个segment的部分buffer,然后对所有buffer进行Merge。然后对然后当某一个segment的部分buffer读取完成,会继续读取这个segment的下一块buffer,将这块buffer继续加到merge过程中。
这样有一个问题,Reduce端从ShuffleServer读取数据的次数大约为为segments_num * (segment_size / buffer_size),对于大任务这是一个很大的值。过多的RPC意味着性能的下降。
由于Reduce端内存有限,为了避免在Reduce端进行Merge的时候spill数据到磁盘。Reduce在获取Segment只能读取每个segment的部分buffer,然后对所有buffer进行Merge。然后对然后当某一个segment的部分buffer读取完成,会继续读取这个segment的下一块buffer,将这块buffer继续加到merge过程中。
这样有一个问题,Reduce端从ShuffleServer读取数据的次数大约为为segments_num * (segment_size / buffer_size),对于大任务这是一个很大的值。过多的RPC意味着性能的下降。
这里的segment是指排序后record集合,可以理解为record已经按照key排序后的block。
- 优点: Shuffle Server不需要做额外的任何事情。
- 缺点: 过多的RPC。
本文选择方案1,接下来的内容主要针对于方案1进行讨论。
3 需求分析
3.1 哪类任务需要远程merge?
当前uniffle的map端操作已经不再需要磁盘操作。本文主要考虑reduce端的情况。主要分如下几种情况:
- (1) 对于spark的非排序且非聚集、tez unordered io,Record是来之即用的,不需要有任何的全局的聚合和排序操作,只需要非常少的内存。当前版本的uniffle在内存设置合理的情况下是不会使用磁盘的。使用当前uniffle的方案即可。本文不会讨论这方面的内容。
- (2) 对于spark的排序或聚集任务、tez ordered io、mapreduce,由于需要全局排序或聚集,内存可能不够用,可能会将Record spill到磁盘。本文主要讨论这种情况。
综上可知,remote merge仅用于需要排序或聚集的shuffle。
3.2 ShuffleServer如何进行排序?
对于排序类的操作,一般会在Map进行排序得到一组局部排序的记录,这里称之为segment。然后Reduce会获取所有的segment, 并进行归并,Spark, MR, Tez都是用了最小堆K路归并排序。远程排序依旧可以使用这种方式。
BufferManager和FlushManager维护着block在内存和磁盘中的信息。我们只需要在需要在ShuffleServer中新增MergeManager,并将同一个Shuffle下的block进行Merge,得到全局排序的Records即可。
在ShuffleServer端引入排序后产生一个副作用: 即需要将该Shuffle的KeyClass和ValueClass以及KeyComparator传递给ShuffleServer。
3.3 ShuffleServer禁止combine
Combine一般都是用户自定义的操作,因此禁止ShuffleServer端进行Combine操作。
4 架构设计
4.1 RemoteMerge的基本流程

下面介绍一下Remote Merge的流程:
- (1) 注册
AM/Driver调用registerShuffle方法,会额外注册keyClass, valueClass和keyComparator. 这些信息主要用于ShuffleServer在合并的时候对Record进行解析和排序。 - (2) sendShuffleData
sendShuffleData逻辑与现有的RSS任务基本保持一致。唯一区别是使用统一的序列化器和反序列化器,这样可以保证无论是哪一种框架,ShuffleServer都可以正常的解析Record. - (3) buffer and flush
shuffle server端会将数据存在缓存中,或者通过flush manager缓存到本地文件系统或远程文件系统。这里还是复用原来的ShuffleServer的逻辑。 - (4) reportUniqueBlocks
提供了一个新的API, 即reportUniqueBlocks。Reduce端会根据map产生的block进行去重,然后将得到有效block集合通过reportUniqueBlocks发送给ShuffleServer。ShuffleServer收到有效的blocks集合后,会触发Remote Merge。Remote Merge的结果会像普通的block一样写入到bufferPool, 避免的时候会flush到磁盘中。RemoteMerge产生的结果即为普通的block,但是为了方便说明,这里称之为merged block。merged block记录的是按照key排序后的结果,因此读取merged block的时候,需要按照blockid的顺序依次递增读取。 - (5) getSortedShuffleData
Reduce会按照block序号的顺序读取merged block,然后根据一定的条件选择何时为reduce计算使用。
4.2 从Record的视角分析流程
我们可以WordCount为例子解释Record在整个过程中的流转。本例子中有两个分区以及一个Reduce,即一个Reduce处理两个分区的数据。
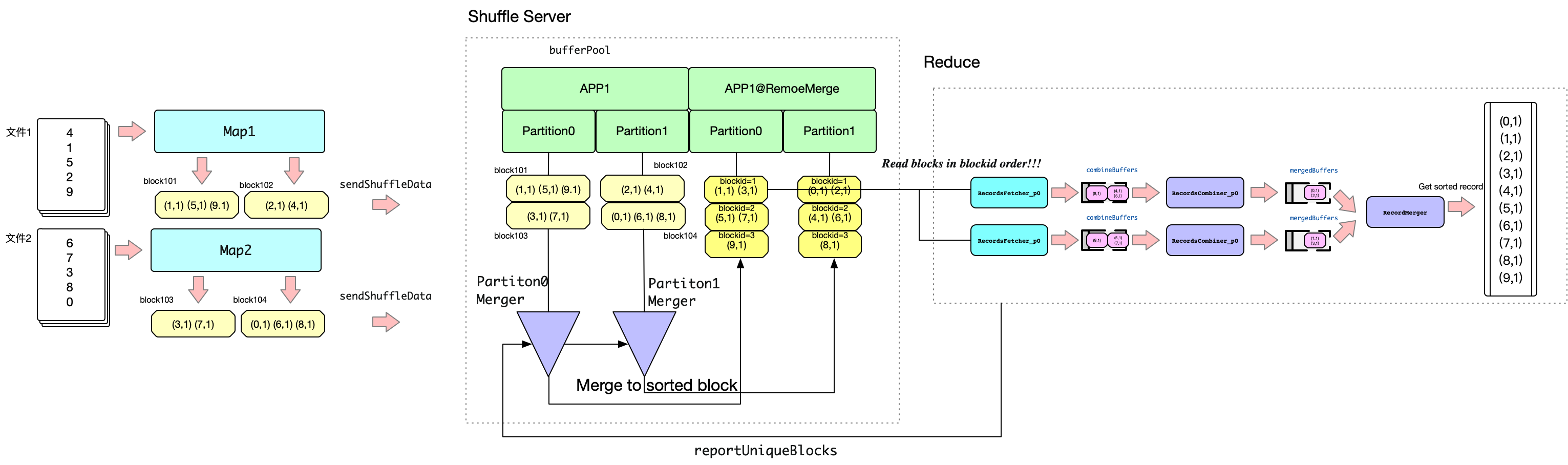
- (1) MAP端
Map端处理文档数据后,会进行排序。对于Map1, 由于存在两个分区,以奇数为key的record会写入到block101中,以偶数为key的record会写入到block102中。Map2同理。注意这里block中的Record都是已经排序后的。 - (2) Map端发送数据
Map端通过sendShuffleData将block发送给ShuffleServer, ShuffleServer会将其存储到bufferPool中。
这里指的注意的是,在注册的时候会会注册APP1名字的app的同时,也会注册APP1@RemoteMerge的app,稍后会介绍它。 - (3) ShuffleServer端Merge
Reduce启动后,会调用reportUniqueBlocks汇报可用的block集合,同时触发ShuffleServer中对应的partition进行Merge。Merge的结果在这个分区下全局排序的Record集合。
然后的问题是Merge的结果存在那里?Merge过程是在内存中发生的,每当Merge一定数量的Record后,会将这些结果写到一个新的block中。为了与原来的appid区分,这里会将这组block放在一个以”@RemoteMerge”结尾的appid进行管理。这组新的block的blockid是从1开始递增的,而且是经过全局排序的。即每个block内部的record是排序的,blockid=1的records一定小于等于blockid=2的records。 - (4) Reduce端读
根据前面的分析,Reduce端只要读取以”@RemoteMerge“结尾的appid管理的block即可。Reduce读取block的时候从blockid=1的block开始,按照blockid顺序读取即可。我们知道Reduce进行计算的时候,是按照顺序计算的。由于我们在ShuffleServer端获取的数据已经是排序后的,所以每次只需要从ShuffleServer端获取少量的数据即可,这样就实现了从ShuffleServer端按需读取,大大降低了使用内存。
这里还存在两种特殊的情况,详细5.5
5 计划
5.1 统一序列化器
由于需要在ShuffleServer端进行Merge, 需要提取出独立于计算框架的统一序列化器。这里提炼出两类序列化器: (1) Writable (2) Kryo。Writable序列化用于处理org.apache.hadoop.io.Writable接口的类,用于MR和TEZ框架。Kryo可以序列化绝大多数的类,一般用于Spark框架。
5.2 RecordsFileWriter/RecordFileReader
提供关于处理Record的抽象方法
5.3 Merger
提供基础的Merger服务,对多个数据流按照key进行merge。采用最小堆K路归并排序,对已经进行局部排序的数据流进行归并排序。
5.4 MergeManager
用于在服务端对Records进行Merge。
5.5 RMRecordsReader
一般来讲Reduce端在读取数据的情况,直接发给下游计算即可。但是存在两种特殊的情况:
(1) 对于存在需要在Merge进行combine的情况,我们需要等待所有相同的key都达到后进行combine,然后再发给下游。
(2) 对于spark和tez, reduce端可以会读取多个分区的数据。因此我们需要对多个分区的数据在reduce端再进行一次merge,然后在发给下游。
RMRecordsReader是用于读取排序后数据的工具。大致的架构如下:

图中描述了单个Reduce处理两个分区的情况。RecordsFetcher线程会读取对应分区的block,然后解析成Records。然后发送到combineBuffers中。RecordCombiner从combineBuffer中读取Records,当某个key的所有records都收集完成,会进行combine操作。结果会发送给mergedBuffer。RecordMerge会获取所有mergedBuffer,然后在内存中再进行一次归并排序。最终得到全局排序的结果给下游使用。
5.6 框架适配
适配MR,Tez,Spark三种架构。
笔者已使用线上任务对MR和Tez进行了大规模压测。Spark目前仅进行了一些基础的examples的测试,仍需要大量测试。
5.7 隔离的classloader
对于不同版本的keyclass, valueclass以及comparatorclass, 使用隔离的classloader加载。
5 特别注意
- 不支持spark的javardd,因为spark javardd的类型会被擦除。
- 适当提高服务器的max open file的配置。因为合并的时候可能会长时间持有文件。
- 适当降低rss.server.buffer.capacity, 因为remote merge的过程需要更多的额外内存。